知識の本質は言い換えである。文章の中には、様々な知識が詰まっていて、それらは部分的な言い換え、部分知識である。という前提のもとに自然言語解析を行なっているが、その入り口のところのprologプログラムを記録しておく。
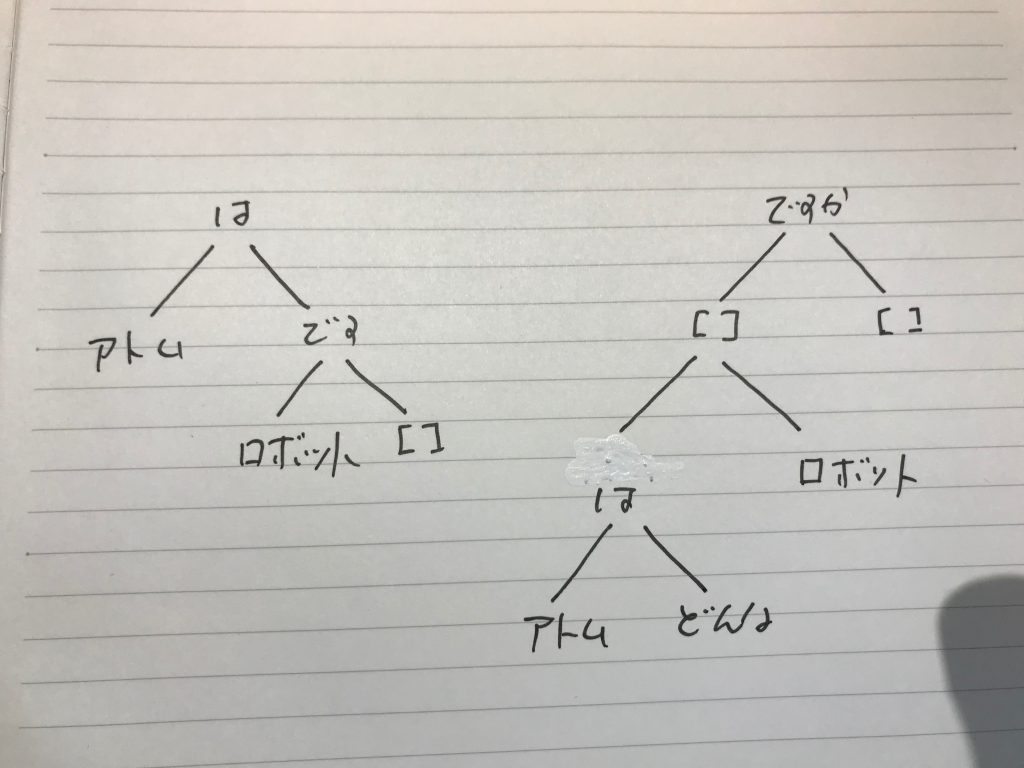
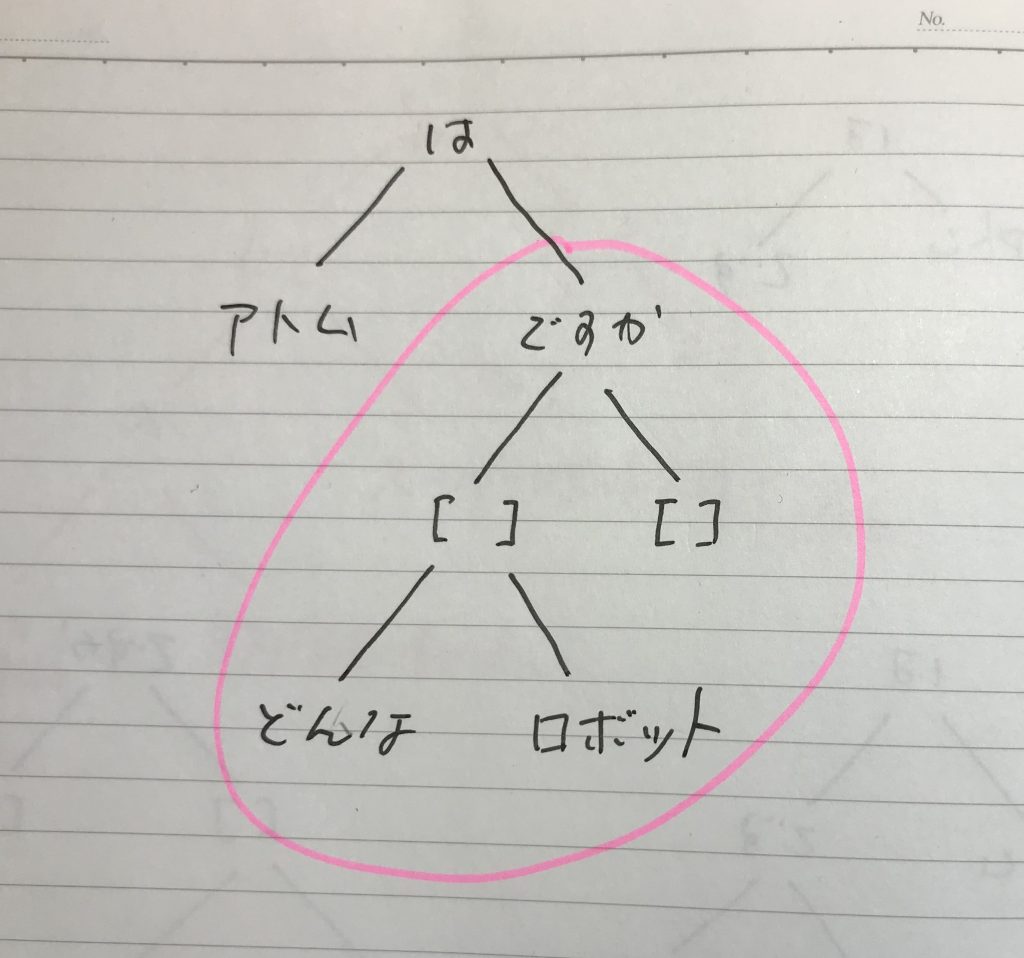
prologの二分木化された文章例は以下のようなものである。wikipediaからの一文である。
jawiki(wiki_543_line_2261_1,
node(を,
小田,
node([],
[含む, 'V:含む'],
node(は,
['4', [名, 'C:抽象物']],
node(に,
node([],
node(ばかりの,
node(が,
[放送, 'C:抽象物'],
[[終了, 'C:抽象物'], [した, 'V:する']]
),
[アニメ, 'C:抽象物']
),
[[[機動, 'C:抽象物'], [戦士, 'C:人']], ガンダム]
),
node([],
[[[熱中, 'C:抽象物'], [して, 'V:する']], おり],
node(の,
node([],
node([],
node(に,
node(から,
node([],
node(が,
node([],
まだ,
ガンプラ
),
[[[発売, 'C:抽象物'], [さ, 'V:する']], れる]
),
前
),
[同, [作品, 'C:抽象物']]
),
[[登場, 'C:抽象物'], [する, 'V:する']]
),
[[ロボット, 'C:人工物-その他'], [兵器, 'C:人工物-その他']]
),
'モビルスーツ(MS)'
),
node(を,
[模型, 'C:人工物-その他'],
node([],
[[[自作, 'C:人工物-その他'], [して, 'V:する']], いた],
[ ]
)
)
)
)
)
)
)
)
).
冒頭にもあるように、もと文章は、日本語wikipediaのテキスト化ファイルの543番ファイルの2261パラグラフ目にある文章で、
「小田を含む4名は、放送が終了したばかりのアニメ『機動戦士ガンダム』に熱中しており、まだガンプラが発売される前から同作品に登場するロボット兵器「モビルスーツ (MS)」の模型を自作していた」
をprologの二分木化してものである。
この中にある部分知識を、動詞を原形で終わらせた、一つの整合的な文章と理解して抜き出すプログラムをprologで作成した。次のようになる。
%% -----------------------
%% リストから動詞の原形を取得する 原形までの名詞もつなげる
%% ex. [[[正式, [発表, 'C:抽象物']], [さ, 'V:する']], れた] を 「正式発表する」 に変換
%% 先行するフレーズを取得し、部分知識として獲得する
%% グローバル変数 ws_endverb ws_prewords ws_pushedword を使用する
%% 2019年4月30日〜
%% -----------------------
ws_testverb :- jawiki(_,Node),
%% 初期化が必要なグローバル変数
nb_setval(ws_prewords,[]),
nb_setval(ws_pushedword,'NOTDEFINED'),
ws_getverb(Node,Out),
format('EndWD = ~w ~n',[Out])
.
%% -----------------------
%% ws_memory/2
%% 言葉の記憶数:先行する語をいくつまで記憶しておくか
%% -----------------------
ws_memory(10).
%% -----------------------
%% ws_getverb/2
%% -----------------------
ws_getverb(A,_) :- atomic(A),fail.
ws_getverb(node(_,Left,_),Out) :-
nb_setval(ws_endverb,''),
ws_getoriginal(Left,Out),
nb_getval(ws_prewords,S),
nb_setval(ws_prewords,[]),
format('PreWD = ~w ',[S]).
ws_getverb(node(_,Left,_),Out) :-
ws_memory(M),
ws_pushglobal(ws_prewords,Left,M),
ws_getverb(Left,Out).
%format('DEBUG Left2 = ~w ~n',[Left]).
ws_getverb(node(A,_,Right),Out) :-
ws_memory(M),
ws_pushglobal(ws_prewords,A,M), %% 左から右に変わるときにNode値を確保する
nb_setval(ws_endverb,''),
ws_getoriginal(Right,Out),
nb_getval(ws_prewords,S),
nb_setval(ws_prewords,[]),
format('PreWD = ~w ',[S]).
ws_getverb(node(_,_,Right),Out) :-
ws_memory(M),
%% 右に [同, [作品, 'C:抽象物']] と言うのがあるとここで処理
%% 左も同じ機能
ws_pushglobal(ws_prewords,Right,M),
ws_getverb(Right,Out).
%% -----------------------
%% ws_pushglobal/3
%% グローバル変数に値を左から詰める
%% リストに限定する
%% -----------------------
ws_pushglobal(VName,Term,Size) :-
%format('DEBUG Push Term = ~w ~n',[Term]),
nb_getval(VName,S0),
%format('DEBUG Push S0 = ~w Term = ~w ~n',[S0,Term]),
(atom(Term),
not(last(S0,Term)) %% 既存最終項が重なっていないかだけチェック
-> (length(S0,Size1),
Size1 >= Size
-> [_|T] =S0,
append(T,[Term],S1)
; append(S0,[Term],S1)
)
; ([_|_] = Term, % Termがリストならば
%% カテゴリ等を除いたリストを得る
ws_getlist(Term,L2),
%% そのリストをつなげてatomにする
%%format('DEBUG Pushglobal Term = ~w L2 = ~w ~n',[Term,L2]),
%%format('DEBUG Pushglobal Term = ~w S0 = ~w ~n',[Term,S0]),
flatten(L2,L3),
%% すでにグローバル変数に、このリストの統合した後が、個別に入っている可能性がある
%% もし入っていたら、最後の方から、それに一致するものを全て削除する
%format('DEBUG Pushglobal S0 = ~w L3 = ~w ~n',[S0,L3]),
ws_deletelast(S0,L3,S2),
%%S2 = S0,
concat_atom(L3,H),
%format('DEBUG Pushglobal Term = ~w S0 = ~w ~n',[Term,S0]),
not(last(S2,H))
-> (length(S2,Size1),
Size1 >= Size
-> [_|T2] =S2,
append(T2,[H],S1)
; append(S2,[H],S1)
)
;S1 = S0
)
),
nb_setval(VName,S1).
%% -----------------------
%% ws_getlist/2 (sentence.swiなどにすでに使われている、重複を避けること)
%% -----------------------
%% getlistは、リストが[語, カテゴリ]から構成されているのから、語だけのリストを作る
%% 一つのフレーズに複数の語があると
%% [[[語, カテゴリ],語],[語, カテゴリ]] などのように繋がってリスト化される
%% knpがカテゴリを出力しない場合は、語が単独になることもある
%% HeadとTailをから、それぞれの語を取り出して、結合したのを出力
%% -----------------------
ws_getlist([H|[T]],[X1, X2]) :- ws_getlist(H,X1),
ws_getlist(T,X2),!.
%% 構造的に、Tailには、単位リストしか入っていない
ws_getlist([H|[T]],[H,H1]) :- atom(H),[H1|_] = T,!.
%% tailがリストでない場合は、atomであるHeadのチェック
ws_getlist([H|[_]],[H]) :- atom(H).
%% tailが構造化されたリストの場合にはここで処理する
ws_getlist([H|[T]],[Z,T]) :- atom(T),
ws_getlist(H,Z).
%% -----------------------
%% ws_popglobal/2
%% グローバル変数の最後の要素を取得する
%% グローバル変数は、リストでなければならない
%% -----------------------
ws_popglobal(VName,Term) :-
nb_getval(VName,S0),
%format('DEBUG POPGLOBAL Term = ~w S0 = ~w ~n',[Term,S0]),
(S0 = []
-> Term = [] %% Term = '' の方がいいと思う
; (last(S0,Term)
-> delete(S0,Term,S1),
nb_setval(VName,S1)
; true % これを入れないと全体がfailになってしまう
)
).
%% -----------------------
%% ws_popglobalfromlist/2
%% リストからポップする → 使っていない
%% -----------------------
ws_popglobalfromlist(VName,List) :-
nb_getval(VName,L),
ws_deletelast(L,List,Out),
nb_setval(VName,Out).
%% -----------------------
%% ws_deletelast/3
%% ws_pushglobalの中で使っている
%% Lの最後から L1と一致するものを全て削除する
%% L=[a,b,c,d,e,f,g] L1=[e,f,g] → Out=[a,b,c,d]
%% もし、一致しないものがあったら、元のリストをそのまま返す
%% -----------------------
ws_deletelast([],_,[]). %% 元リストが空の場合は、空を返す これを入れないと空がエラーになる
ws_deletelast(Out,[],Out).
ws_deletelast(L,L1,Out) :-
reverse(L,L0),
[H0|T0] = L0,
reverse(L1,L2),
[H2|T2] = L2,
(H2 == H0
-> reverse(T0,R0),
reverse(T2,R2),
ws_deletelast(R0,R2,Out)
; Out = L % 等しくないものがあった場合は、元のを変更せずに返す
).
%% -----------------------
%% ws_getoriginal/2
%% -----------------------
ws_getoriginal([H0|T],Out2) :-
%% 動詞の場合、H0:表現形, H1:原形
%% atomでなければならない
atom(H0),
[H1|_] = T,
atom(H1),
atom_codes(H1,S1),
%% 'V:' のコードリストは [86, 58]
%% 一致する場合、動詞の原形である
(ws_listncomp([86,58],2,S1)
-> split_string(H1,":","", [_|[T2]]),
atom_string(Out1,T2),
nb_getval(ws_endverb,Out0),
%%atom_concat(Out0,Out1,Out2),
format(atom(Out2),'~w~w/~w',[Out0,Out1,H0]),
%% 動詞に組み込まれた先行語をpopする
nb_getval(ws_pushedword,PW),
%format('DEBUG ws_prewords PW = ~w H0 = ~w ~n',[PW,H0]),
ws_popglobal(ws_prewords,PW)
;
%format('DEBUG H0 = ~w H1 = ~w ~n',[H0,H1]),
Out1 = H0,
nb_getval(ws_endverb,Out0),
atom_concat(Out0,Out1,Out2),
ws_memory(M),
ws_pushglobal(ws_prewords,H0,M),
%% ここでpushしたものを記憶しておき、動詞に入った場合は上でpopする
nb_setval(ws_pushedword,H0),
%format('DEBUG ws_prewords PUSH H0 = ~w ~n',[H0]),
nb_setval(ws_endverb,Out2),!,fail %% !とfailは、ともに不可欠
).
ws_getoriginal([H|_],_) :- atom(H),
%format('DEBUG H_2 = ~w ~n',[H]),
nb_getval(ws_endverb,Out0),
Out1 = H,
atom_concat(Out0,Out1,Out2),
nb_setval(ws_endverb,Out2),!,fail. %% !,failは不可欠
ws_getoriginal(A,_) :- atom(A),
%% C:やC:抜きで入っている単体の語をひろう
%format('DEBUG A = ~w ~n',[A]),
ws_memory(M),
ws_pushglobal(ws_prewords,A,M),fail.
% 左がリストになっている場合
ws_getoriginal([H|_],Out) :-
ws_getoriginal(H,Out).
% 右がリストになっている場合
ws_getoriginal([_|[T]],Out) :-
ws_getoriginal(T,Out).
%% -----------------------
%% ws_listncomp/3
%% -----------------------
%% リストのN番目までリストを比較する
ws_listncomp(_,0,_).
ws_listncomp([H0|T0],N,[H1|T1]) :-
N > 0,
N_1 is N-1,
H0 == H1,
ws_listncomp(T0,N_1,T1),!.
このプログラムの末尾に、先のwikipediaのprolog二分木をくっつけるか、別ファイルにしてそれぞれを読み込む必要がある。プログラムは、何日もかけて改訂しているもので、説明する気が起きないくらい複雑なものだ。
実行例は次のようになる。
?- ['verb.swi'].
true.
?- ws_testverb.
PreWD = [小田,を] EndWD = 含む/含む
true ;
PreWD = [含む,4名,は,放送,が] EndWD = 終了する/した
true ;
PreWD = [終了した,ばかりの,アニメ,機動戦士ガンダム,に] EndWD = 熱中する/して
true ;
PreWD = [熱中しており,まだ,ガンプラ,が] EndWD = 発売する/さ
true ;
PreWD = [発売される,前,から,同作品,に] EndWD = 登場する/する
true ;
PreWD = [登場する,ロボット兵器,モビルスーツ(MS),の,模型,を] EndWD = 自作する/して
true ;
false.
?- ^D
先のプログラムを verv.swiとして、swi-prologに読み込んで、実行している。
PreWDは、先行語(ノード値と左右葉の語)、動詞に先行するフレーズであり、プログラム上、10語までのものを取り出す設定にしている(ws_memory(10).で定義されている)。その後に、動詞の原形という(EndWD)終了後で、部分文章は閉じるようになっている。先行語はどこまでが構成要素になるかは、柔軟に考えれば良い。基本、最低、前の二つの語を採用すればいいだろう。
最初に、「小田を含む」という自立したフレーズ、部分文章、部分知識を取り出す。次が「終了したばかりのアニメ機動戦士ガンダムに熱中する」、「ガンプラが発売する」は文章的には少し変になっている、そして「同作品に登場する」、最後は「ロボット兵器、モビルスーツ(MS)の模型を自作する」となる。
一つの文章からはこのような部分文章を引き出せるが、wikipediaとtwitterの膨大なデータを用いて、これを会話の中に適合的なフレーズに鍛錬する必要がある。
次に、文章構成の基本的な手続きを再び確認したい。