ロボットに舞台で喋らせる時、構成した情報について、文章を短くしたい時、要約したい時が頻繁にあったが、ぶち切れのまま喋らせたりしていた。実に不自然だ。そのため、文章の終わり方については、とても気になる。
これまでに示してきた、wikipediaのprolog化した宣言文での文章の終わり方のパターンを調べてみた。まず、全体的な状況を見ると次のグラフのようになる。縦軸は、文章の頻度だ。(ただし、体言止めは、含んでいない:1割以上が体言止めという感じもあるが、文章の正規の終わり方ではないので除外した)
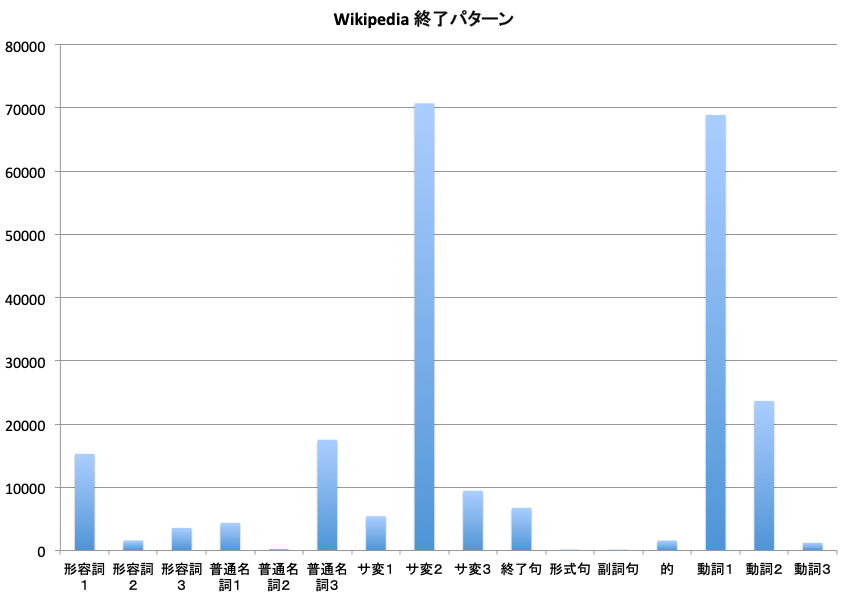
一番多いのは、サ変2というパターンである。例としては次のようなものがある。
実現(S:サ/C:抽象物)さ(V:する)れている→実現されている
発注(S:サ/C:抽象物/D:ビジネス)した(V:する)→発注した
成功(S:サ/C:抽象物)し(V:する)なかった→成功しなかった
すなわち、サ変の名詞があって、それにするという動詞の活用形がきて、語尾がある(活用形が原型などの場合は、語尾はない)Vの右側は、動詞の原形である。jumanppが提供する。
サ変名詞で終わりたい時は、文章的には簡単である。prolog二分木では、サ変名詞を確実に把握できるので、サ変名詞のあるところでは、自由に、自然に、文章を終われる。
次に多いのは、動詞1という終わり方である。これは、動詞を最も単純に使って文章を終わりにさせる方法である。例としては、
示して(V:示す)いる
下して(V:下す)いる
こなして(V:こなす)いる
用い(V:用いる)られる
考え(V:考える)られない
言わ(V:言う)れる
語ら(V:語る)れた
描く(V:描く)
いう(V:いう)
ある(V:ある)
など。
jumanppは、動詞の原形を必ずくれるので、動詞が来れば、多様な形で文章を終わらせることができる。
ただ、原型から、活用形を導き出す場合、原型の最後の1文字を変更するのが基本的な方法だが、「行う」が「行って」と「って」になるパターンがある。このルールが、私には複雑でよくわかっていない。データベースに動詞のパターンを登録しておくのが、一番簡単なように思える。
次の「動詞2」というのは、終わりのフレーズに動詞が二つある場合だ。たとえば、
溶け(V:溶ける)込んで(V:込む)いる
描き (描く) 出さ (出す) れている
成り (成る) 込む (込む)
受け入れ (受け入れる) なければなら (なる) なくなっている
などのパターンである。
次に多い、普通名詞3は、
劇場 (普) 上映 (サ) さ (する) れた
全面 (普) 開放 (サ) さ (する) れた
毎正時 (普) 送出 (サ) さ (する) れる
社名 (普) 変更 (サ) して (する) いる
行政 (普) 移管 (サ) して (する) いる
など、普通名詞とサ変名詞が連結しているパターンである。
最も単純な、終句で終わるパターンは、7位と意外に少ない。これは、ほとんどの場合、ノードの値が終わりになっている場合だと思う。全部を調べてみた。
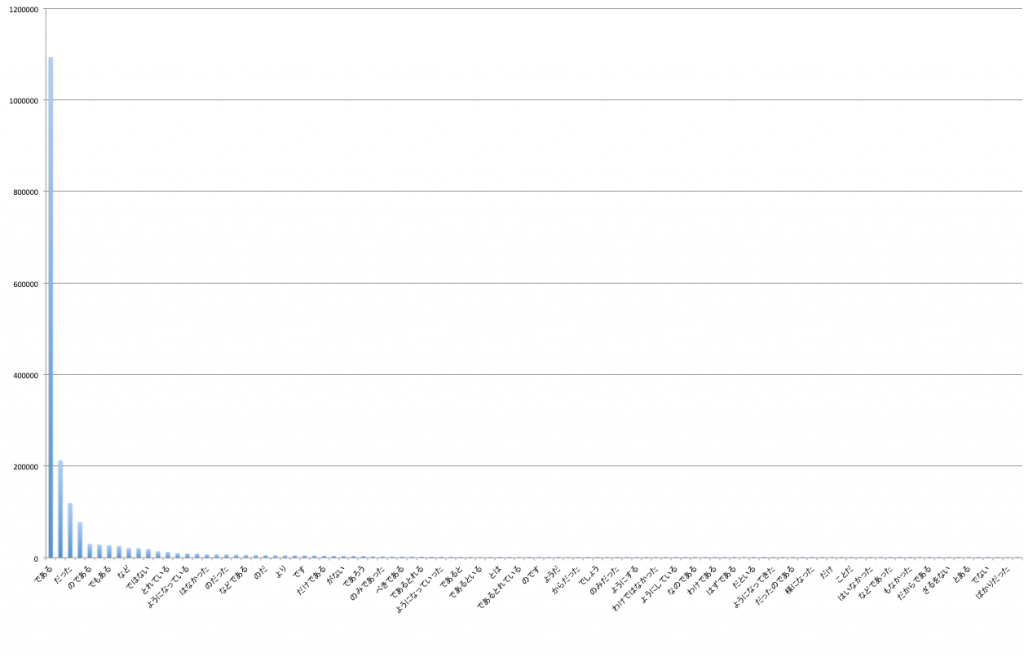
縦軸は、文末に現れる頻度である。ちょっとみにくいが、圧倒的に「である」が多い。あとはカスみたいなものである。Wikipediaは「である」調なので、デスマス調の場合は「です」ということになる。「である」は、その前の言葉にあまり依存しないとても便利な終わりの句である。否定の時は、「ではない」、受け身の時は、「られる」とかにすればよい。