前の記事まででやった、文章のprolog化、二分木化する場合に、もっといろいろ考えるべきことがあるのに気づいた。
題材として、川端康成「雪国」の冒頭の一文をprolog化しよう。
まず、cabochaで、形態素解析および構文解析しておこう。
* 0 2D 0/1 1.211902
国境 名詞,一般,*,*,*,*,国境,コッキョウ,コッキョー
の 助詞,格助詞,一般,*,*,*,の,ノ,ノ
* 1 2D 0/0 2.895743
長い 形容詞,自立,*,*,形容詞・アウオ段,基本形,長い,ナガイ,ナガイ
* 2 3D 0/1 1.600771
トンネル 名詞,一般,*,*,*,*,トンネル,トンネル,トンネル
を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ
* 3 4D 0/1 1.600771
抜ける 動詞,自立,*,*,一段,基本形,抜ける,ヌケル,ヌケル
と 助詞,接続助詞,*,*,*,*,と,ト,ト
* 4 -1D 0/3 0.000000
雪国 名詞,一般,*,*,*,*,雪国,ユキグニ,ユキグニ
で 助動詞,*,*,*,特殊・ダ,連用形,だ,デ,デ
あっ 助動詞,*,*,*,五段・ラ行アル,連用タ接続,ある,アッ,アッ
た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ
EOS
英語のような明確な主語を持たない、日本語らしい文章だ。1フレーズの形容詞句を除いて、全て、助詞か助動詞があり、フレーズをシーケンシャルに結合させている。*のラインの第2項に示されている2Dなどが示している係り受け解析は、単純に語順を再現しているだけである。雪国を含むフレーズにある、-1D は、その句が、それ以上、どこにもかかっていないことを示している。
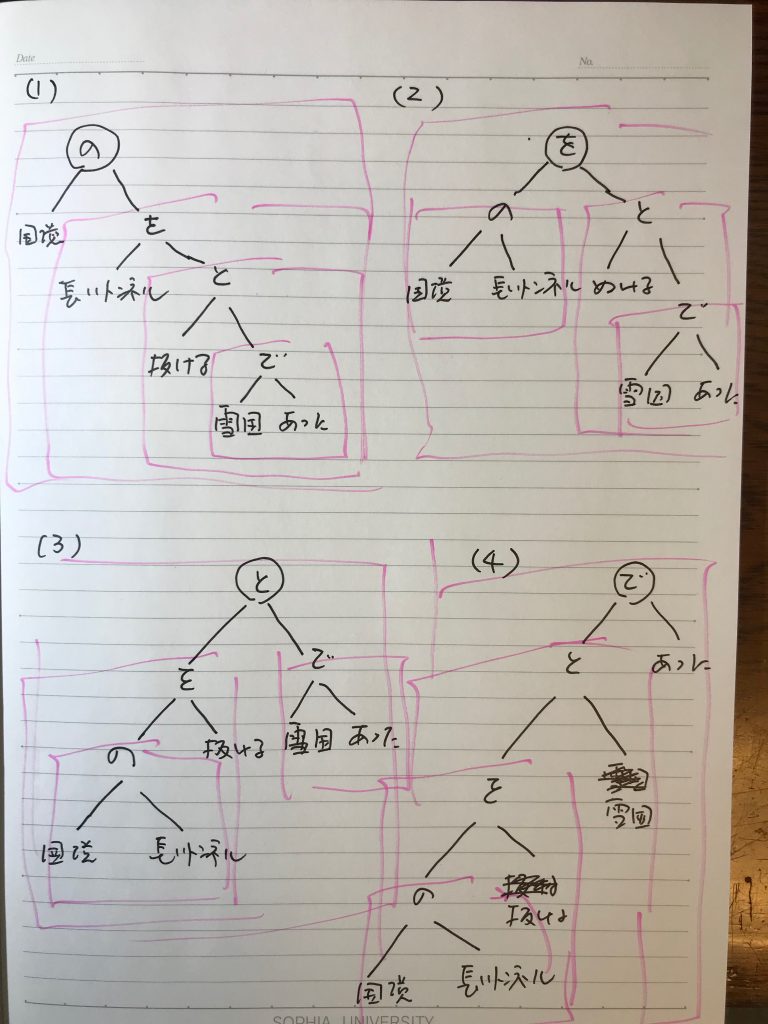
そこで、これを前と同様にprologの二分木に変更してみよう。ただし、ここでは、4バージョンの二分木があるのを全て書き下すことにする。(前の記事までの芸人の定義では、一つの直感的prolog化だけを用いた)
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%% 川端康成『雪国』冒頭
%% 「国境の長いトンネルを抜けると雪国であった」
%% 一行で表示する場合をコメントで示したのちに、インデント付きで表示する
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%% (1)
%% 一行表示
%% yukiguni1(node(の, 国境, node(を, [[長い], トンネル], node(と, 抜ける, node(で, 雪国, あった))))).
%% インデント表示
yukiguni1(
node(の,
国境,
node(を,
[[長い],トンネル],
node(と,
抜ける,
node(で,
雪国,
あった
)
)
)
)
).
%% (2)
%% yukiguni2(node(を, node(の, 国境, [[長い], トンネル]), node(と, 抜ける, node(で, 雪国, あった)))).
yukiguni2(
node(を,
node(の,
国境,
[[長い],トンネル]
),
node(と,
抜ける,
node(で,
雪国,
あった
)
)
)
).
%% (3)
%% yukiguni3(node(と, node(を, node(の, 国境, [[長い], トンネル]), 抜ける), node(で, 雪国, あった))).
yukiguni3(
node(と,
node(を,
node(の,
国境,
[[長い],トンネル]
),
抜ける
),
node(で,
雪国,
あった
)
)
).
%% (4)
%%
%% yukiguni4(node(で, node(と, node(を, node(の, 国境, [[長い], トンネル]), 抜ける), 雪国), あった)).
yukiguni4(
node(で,
node(と,
node(を,
node(の,
国境,
[[長い],トンネル]
),
抜ける
),
雪国
),
あった
)
).
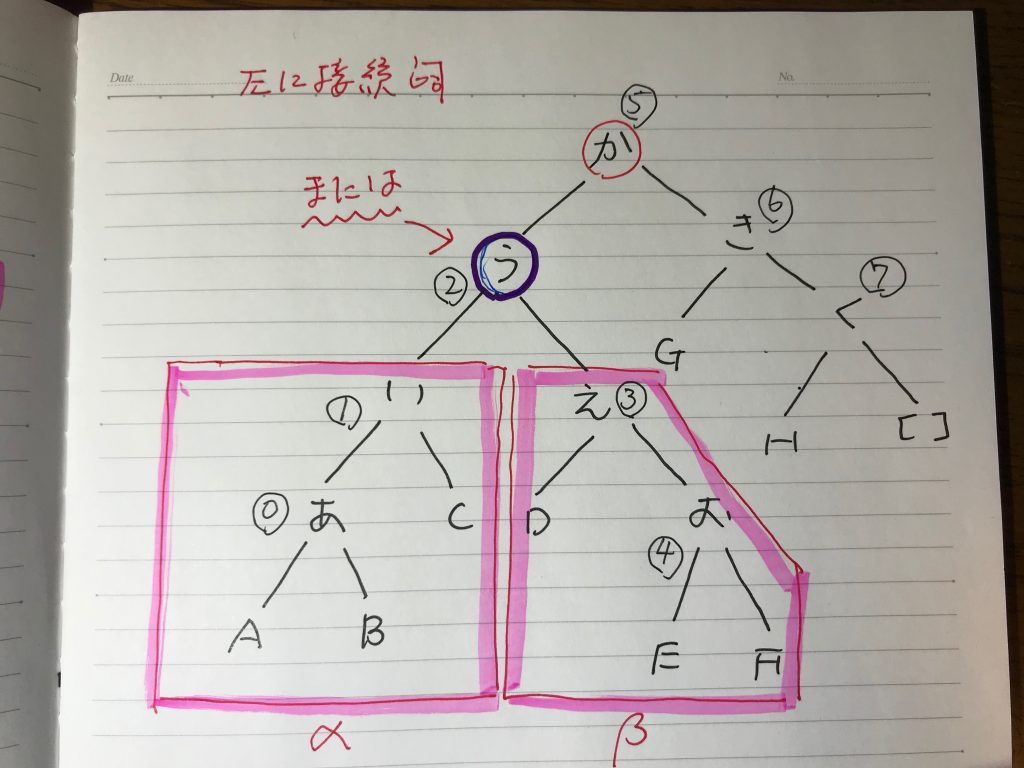
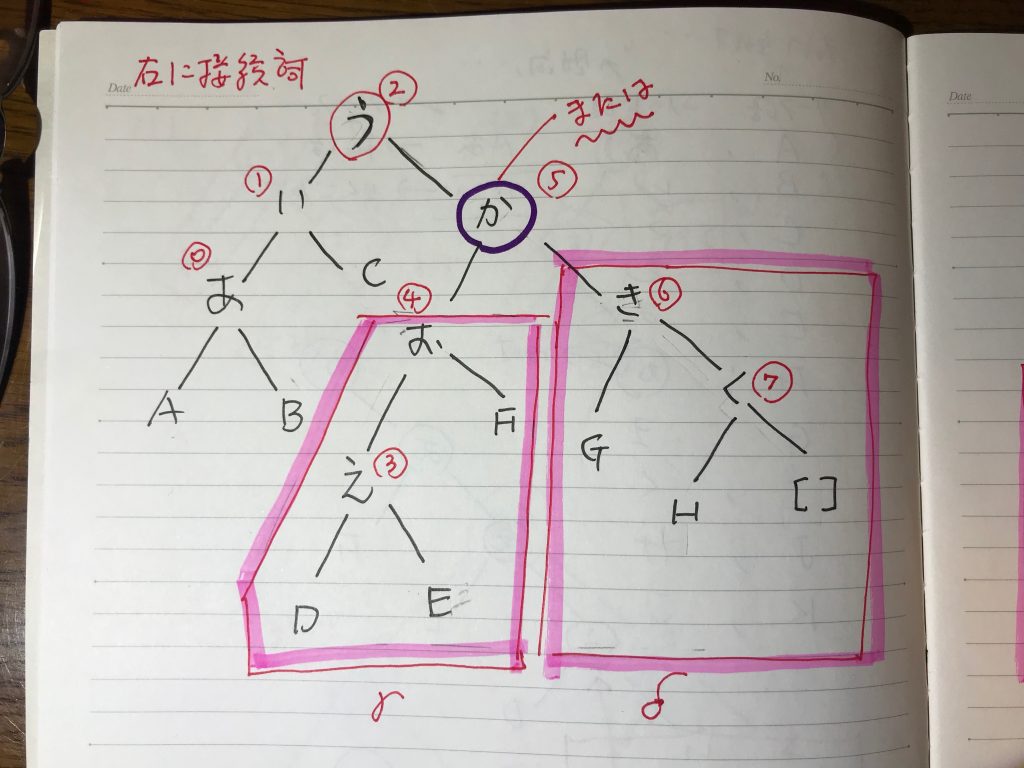
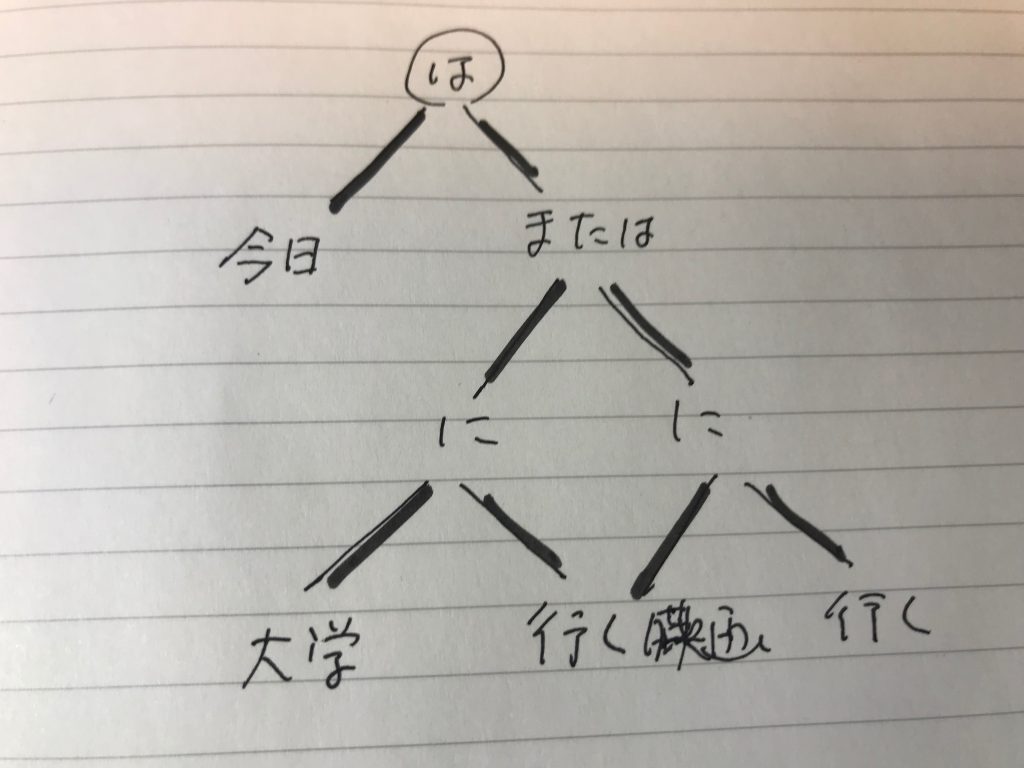
これをyukiguni.swiファイルとして保存し、swi-prologに問題なく読み込ませることができる。これでけでは少しイメージしにくいと思うので、二分木をノートに書いたのが以下の画像である。
4つのバージョンができることがややこしい。この違いついて議論する前に、フォーマットの若干の拡張について触れておく。
基本、名詞や動詞に直接かかる形容詞や副詞は、その名詞や動詞と一体のものとして扱う。cabochaの構文解析でも、「い」は助詞にもなっていない。
トンネルにかかる形容詞は、「長い」の他のも「暗い」などたくさんありうるので、かかる言葉をprologのリストとして扱う。例えば、それは [[長い,暗い],トンネル]でも良いわけである。トンネルは名詞で、ないと思うが、それが活用などの語形変化があれば、トンネルもリスト化すれば良い。そこは、「芸人」の定義分析でやったところである。
また、今回は、動詞の活用形が問題になる語が「あった」と「ある」しかなく、これは記述の簡単化のために無視した(本番では [あった, ある]のリストにすると思う)。
各バージョンについて見ていこう。
(1)cabochaによる構文解析ともっとも整合的なものがこのバージョンである。「雪国であった」というフレーズが、他のノードに依存しない独立化可能なロバスト(頑健:外部に影響されない)なものになっている(これは、(2)と(3)のバージョンに共通している。)。他に、ロバストなフレーズはない。もっとも際立った特徴は、この唯一のロバストなフレーズに、抜ける、長いトンネル、国境という名詞、動詞がシーケンシャルにかかっていることだ。「雪国であった」というフレーズが、絶対的存在感を持つような構造になっている。さらに、全ての左の語から、言葉を始められることである。ちょっとわかりにくい言い方だが、先の芸人の記事において、検索は、右の語を探しに行って、一致したものがあったら、右の語を含めて文章化できるものをその下に向かって作成していった。右の語に独立して存在しなければ、見つけられない仕組みになっていた。しかし、この(1)バージョンでは、そのような独立した右の語は、「あった」しかなく、そこから構成できる文章は「雪国であった」だけだが、同じように左語からの検索と文章構成システムを用いると(それは、前回の記事の中にあるプログラムを若干改訂すればすぐにできる)、全ての部分文章(部分知識)が作り出されることになる。その意味するところは、全ての他のフレーズが「雪国であった」に従属しているのである。
(2)の特徴は、「国境の長いトンネル」というのが、ロバストなフレーズとして独立したことである。そして、「抜けると」というフレーズを接着剤にして「雪国だった」というメインフレーズとつなげられていることになる。
(3)は、(2)と比べて「抜けると」というフレーズが、「国境の長いトンネル」の側により強く繋がっていることが特徴だ。
(4)は、(1)の対称系になっている。「雪国」が単なる飾りのようになってしまった。右語からの検索で、全ての部分文章、部分知識が再現できる。
prologによる文章の知識化としてみたとき、この四つのバージョンのうちのどれを選ぶかが問題である。小説「雪国」冒頭としてみたとき、(4)はしっくりこない。
四つ全てを保持するのは、非効率であることは明らかなので、何らかの知識、言葉、文章を構成するときに、どの形で保持することが効果的かという基準になる。
もともと、このような情報の知識化をprologで行おうという動機になったのは、ロボットに知識を喋らせるときに、どうしても一つの文章を短く、縮約する必要があるのに、単文要約の適切なアルゴリズムが見つからなかったことである。ディープラーニングなどのコンテンポラリな手法にも、最終解決は託せなかった。その過程で読んだ論文に「大規模データを用いた日本語文圧縮」(長谷川駿氏他、2017)があって、その中で「を、に、が、は」は、かかり先文節の必須語になりやすい、と指摘されていた。
それは、言い換えれば、それくらい強い結びつきを作る言葉であるということは「そのような強さを持っていなければならないほど、それによって繋がる二つのフレーズは、相対的に強い独立性を持っている」ということではないか。
この意味をどう解釈するかは別にして、まず、助詞に強さがあることが興味深い。さらに、ここでのシステムに応じた表現に変えれば、これらの語は、二分木ツリーのルートに近いところにあるべきだと解釈しても良さそうである。実際、前節までで使っていたwikipedia芸人の定義は、私が直感的な判断で「芸人とは」の「とは」をルートにしていた。「とは」は「は」とほぼ同じか、それよりも強めの助詞である。
というようなことを考え合わせると、この雪国冒頭の文書の場合も、助詞「を」を二分木のルートとしているバージョン(2)を採用することが妥当のように思える。