DCMを使ってジャンプさせてみた。
目に見えて飛び上がるまでになっていない。ただ、動きは前より格段に早くなった。ジャンプしそうな雰囲気を出しているし、実際 0.5mm くらいは浮いたような気がしないでもない(笑)
DCMを使ってジャンプさせてみた。
目に見えて飛び上がるまでになっていない。ただ、動きは前より格段に早くなった。ジャンプしそうな雰囲気を出しているし、実際 0.5mm くらいは浮いたような気がしないでもない(笑)
NAOQIにDCMのサンプルがついている。=> ココ
fastgetsetsample
という名前になっている。
このなかには、DCMの使い方のいろいろなノウハウが詰まっている。DCMは、単独の動作を直接アクチュエーターやセンサー、LEDに送ることができるが、ここには、同時に、10msecという短い周期で、DCMからよびだすことができるコールバック関数の書き方が示されている。
このコールバック関数に記載すれば、ロボットのボディの全体状況を細かく制御できる。
たとえば、NAOが倒れた瞬間に、すべての関節状態の硬直性を一瞬にゼロにして、破壊を出来る限り回避する力を持っている。これは、NAOが足が地面から離れることをセンサーで感知したり、体の急速な傾きを感知したりして、その瞬間に、Stiffnessをゼロにする操作をしているからである。10msecあれば、その対応は十分できるのだろう。
ジャンプには、このコールバック関数は使わなくてもいいと思った。なにしろ、瞬発力が問題なので。先にも書いたように、コールバックを使わなくても、DCMコマンドを単体で叩いても、高速な動きは作れるからである。
しかし、ジャンプしたあとの体制の制御や、着地のことを考えると、このコールバック関数を使わなくてはならなくなるときが来るような気もするのだ。
NAOをジャンプさせようとして、ぬるい関節の動きに失望したという話を前回に書いた。そして、高次のNAOQIのAPIを使うことをやめて、DCMを直接叩くことにした。
まだ、きちんとコントロールはできていないが、試してみた関節の動きは、「すさまじく高速」だった。これで、ジャンプをさせることはできそうだが、コントロールできるかどうかはわからない。
キレキレのダンスをやらせるためには、ジャンプは不可欠だ。少しでもジャンプできなければ、手と体を揺らしている、そこら辺の動画レベルになってしまう。さしあたって、この間作成したポーズのシーケンススクリプトでジャンプをやらせてみたら、つぎの動画だ。
関節の動きが鈍くて、ジャンプにはならない!!
ギリギリスピードを早めても、だめだ。色々調べると、どうも、NAOQI側で、動きをスムーズにしているようだ。モータに直接アクセスしたい。それをNAOQIのDCMモジュールを操作することで実現できるかもしれない。
そこで、DCMを操作する独自モジュールを作成することにした。
NAOの胴体角度を100msec単位で取得した。図は、NAOを前後左右に揺らした結果である。縦軸は角度で、単位はラジアンである。
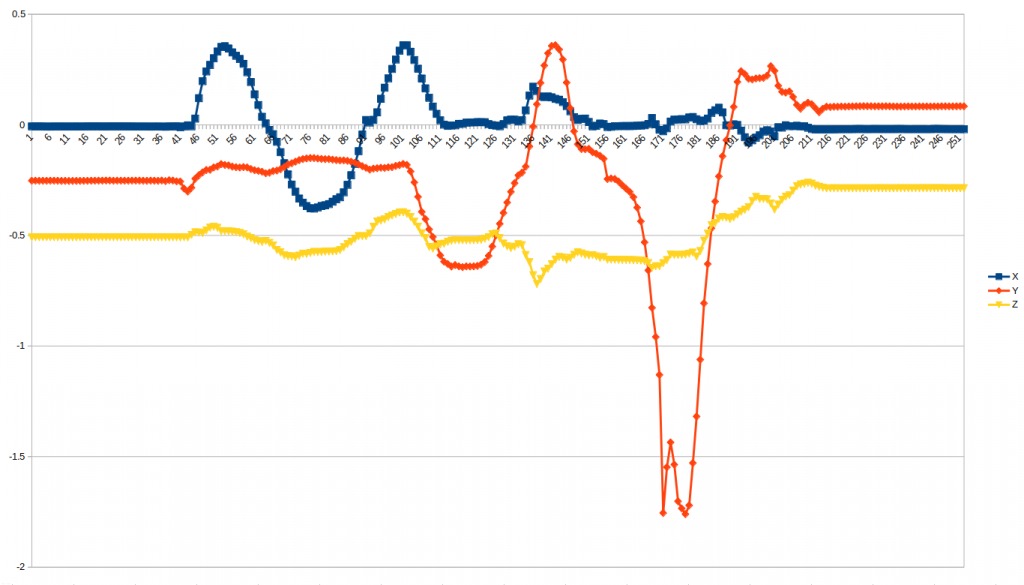
次の3個のキーがあって、メモリイベントとして取得すれば、胴体の絶対角度を取得できる。
Device/SubDeviceList/InertialSensor/AngleX/Sensor/Value Device/SubDeviceList/InertialSensor/AngleY/Sensor/Value Device/SubDeviceList/InertialSensor/AngleZ/Sensor/Value
私が自分で作ったロボットの場合は、地磁気センサーを使って取得したが、NAOは、加速度センサーと角速度センサーから計算しているようだ。
上記の図で、前後の傾きがオレンジである。少しゼロから外れているのは、最初から少し傾いていたということだ。後半に極端な負になっているのは、誤って後側にNAOを倒してしまったからである。Zは、垂直軸の回転で、これは前後左右の傾きのように、直感的なゼロ度が不明である。地磁気の北かと思ったが、そうでもないようだ。地磁気センサーはないのだろう。しかし、縦軸の回転のゼロ度は大きな問題ではない。初期の向きをゼロ度にしておけば良いからだ。
これから、キレキレの踊りをさせるプロジェクトを始めるが、絶対角度は何かに使えるし、使わなくてはならないだろう。
キレキレダンスプロジェクトで、NAO用の姿勢制御モジュール WSSequenceと、それが解釈実行するスクリプト処理言語を作成した。
たとえば、以下のようなスクリプトを解釈して実行する。ポーズの実行、変数処理、ループ、センサー利用などができる。angles005_83などには、この間記載した全アングルの角度設定が入っている。ongroundは、指定の足の着地重量が指定された値以上になるまで待機するコマンドである。
#----------------------------------------------
# Walk005_2.mseq
# スクリプトバージョン 2 に対応
# ※ Stand or StandInit以外の態勢から
# walkなどの足の動作をすると、倒れる!
#----------------------------------------------
# 基本速度を設定
let,$spd,0.8
# 着地センサーのパラメータ設定
# 着地判定重量,判定時間[ミリ秒],時間ステップ[ミリ秒]
setparams,0.8,100,2
# 歩行可能初期状態を実現
execpose,speed,StandInit,$spd
# 50ミリ秒データによる歩行
# 歩行開始プロセス
execpose,speed,angles005_83,$spd
execpose,speed,angles005_84,$spd
execpose,speed,angles005_85,$spd
execpose,speed,angles005_86,$spd
execpose,speed,angles005_87,$spd
execpose,speed,angles005_88,$spd
# $1が 1,2,3 となる3回実行される(C++等とは異なる)
loop,$i,1,3
#歩行の1サイクルを記載
println,第,$i,回、歩行ループ
execpose,speed,angles005_141,$spd
execpose,speed,angles005_142,$spd
println,左足の着地チェック
onground,left
execpose,speed,angles005_143,$spd
execpose,speed,angles005_144,$spd
execpose,speed,angles005_145,$spd
execpose,speed,angles005_146,$spd
execpose,speed,angles005_147,$spd
execpose,speed,angles005_148,$spd
execpose,speed,angles005_149,$spd
execpose,speed,angles005_150,$spd
execpose,speed,angles005_151,$spd
println,右足の着地チェック
onground,right
execpose,speed,angles005_152,$spd
execpose,speed,angles005_153,$spd
end
# 歩行の停止プロセスに入る
execpose,speed,angles005_154,$spd
execpose,speed,angles005_155,$spd
execpose,speed,angles005_156,$spd
execpose,speed,angles005_157,$spd
execpose,speed,angles005_158,$spd
execpose,speed,angles005_159,$spd
execpose,speed,angles005_160,$spd
execpose,speed,angles005_161,$spd
execpose,speed,angles005_162,$spd
execpose,speed,angles005_163,$spd
execpose,speed,angles005_164,$spd
execpose,speed,angles005_165,$spd
execpose,speed,angles005_166,$spd
execpose,speed,angles005_167,$spd
execpose,speed,angles005_168,$spd
# 直立状態を回復する
execpose,speed,Stand,0.2
先の記事にも書いたように、デスクトップにLinux Mintの32ビットバージョンを入れて、naoqi のc++の開発環境を整えようとしている。Chregrapheの問題は、かんたんに解決した。
qibuildの関係で、昨日からすったもんだしている。前のMacのVirtualBoxのLinux Mint 32では、全く問題なく行っていたのだが、新しい状況でC++のモジュールをqibuildでコンパイルしようとすると、大量の警告とエラーが出てにっちもさっちもいかなくなる。
まずうまく行かなかったことを書いておく。
警告は、boostのポインタ絡みであることはわかった。これについては、naoqiのドキュメントのどこかに示してあった、
#define BOOST_SIGNALS_NO_DEPRECATION_WARNING
をおいておけば大丈夫のはずが、出るのだ。まず、boostが新しすぎるのではないかと思って、
sudo apt install libboost-all-dev
で入れ直したり、最初からコンパイルしてインストールしたり(膨大な時間がかかった)したが、だめだった。
結局、boostを全部削除しても、同じ警告だったので、boostではないことはわかった。
すったもんだした末、結局、g++のバージョンを7から4まで下げたことで、警告は出なくなった。VirtualBoxのバージョンと同じにしたのだ。
しかし、まだ、エラーが出る。これは、gccがバージョン7と新しすぎることが原因だと思って、gcc-5.4をコンパイルしたが、結局単なるプログラムミスだった。
結論的に、qibuildは、boostのインストールなしに、gcc-7.3とg++4.8.5で、正常に動いた。良かったよかった。
何しろ古いのである。SoftbankRoboticsさんは、pepperくんのsdkバージョンはどんどん上げていくが、私のようにNAO25のV5などをつかっているとまだ、5年前のSDKを使わざるを得ない。C++ライブラリなんか作っていると、NAOが32ビットなので、何かとそれが必要になるので、linuxもUbuntuがつかえず、Linux Mintになる。
今までは、MACのVirtualBoxにlinuxMintの32ビットをいれて、使っていたが、操作性が今ひとつだった。こんど、また色々開発するので、思い切って古いが結構早いデスクトップにまるごとLinuxmint32をいれた。それでChregrapheもいれたら、
/usr/local/ChoregrapheSuite2.1/bin/choregraphe-bin: error while loading shared libraries: libpng12.so.0: cannot open shared object file: No such file or directory
こんなエラーが出て起動しなくなった。たぶん、Linux Mintが新しすぎてライブラリの整合性がなくなっているのだ。いろいろさぐって、次のように対応した。
mint32:~$ wget -q -O /tmp/libpng12.deb http://mirrors.kernel.org/ubuntu/pool/main/libp/libpng/libpng12-0_1.2.54-1ubuntu1_i386.deb
mint32:~$ sudo dpkg -i /tmp/libpng12.deb
mint32:~$ rm /tmp/libpng12.deb
また起きそうなので、記録のために書いておいた。
先の記事で作成したポーズデータ(50センチ歩行の110セットのデータ)を使って、Choregrapheのバーチャルロボットでシミュレーションしてみた。ほぼ、きちんと歩行を再現している。
左下に実行しているポーズデータのログが出力されている。
次に生ロボットでうまくいくかどうかを試してみる。そうすれば、スピードが実際どうなるか、変えることができるかどうかがわかるだろう。
サリーにキレキレのダンスを踊らせたいと思っている。Youtubeにも上がっているが、それは手の動きが中心で足はただゆっくりと動かしている。それでは、人を惹きつけられない。できれば、ジャンプしたり、ランニングマンなど、最低できなければならない。できるとは確信持てないが、NAOについているモータは相当性能が良いので、うまくコントロールできれば、そして、足の裏などが耐久性を持っていれば、できる可能性があるかもしれないと思う。
そのために、NAOの運動能力を徹底的に調べようと思った。その手始めに、プレインストールされている、NAOの二足歩行を調べる。NAOには、26個の関節があり、まず、歩行時にこの関節がどう動いているのかを調べた。NAOの歩行は、安全のためだと思うが、遅すぎる。尺を取りすぎて、ネタに組み込めないという弱点がある。もっともっと早く歩かせたいのだ。できると思う。調べた結果は以下の通りである。(パソコンから、pythonのnaoqi sdkを使って、ロボットのnaoqiにつなげて、関節データを取得するAPIを使用した)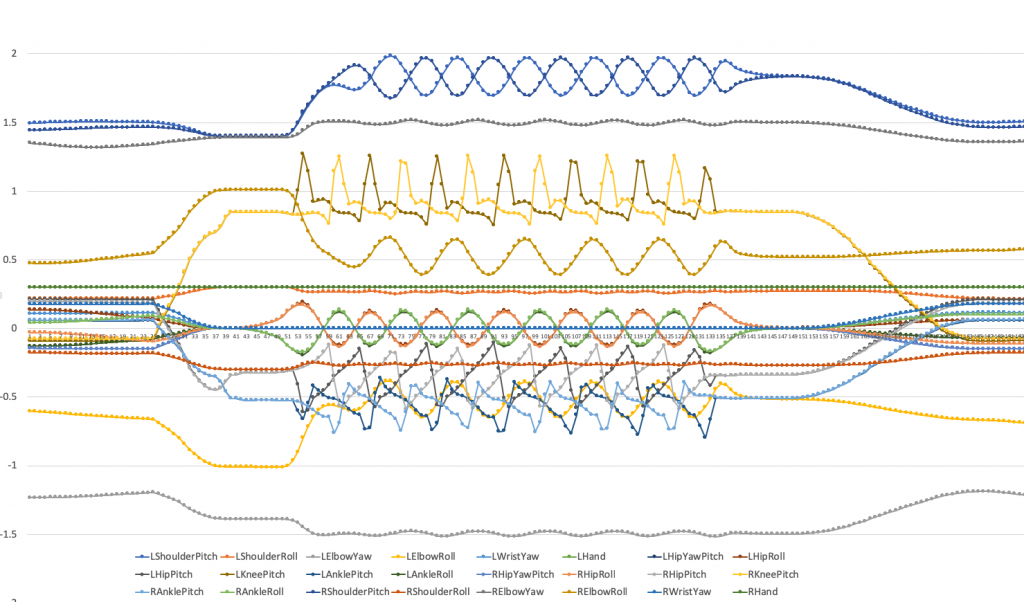
見ての通り、歩行前の静止状態から、歩行準備態勢に入り、歩行(約50センチメートル)、そして、歩行終了の態勢から静止状態に入るプロセスの関節状態である。データは、50ミリ秒ごとにとっている。頭を動かす二つの関節(ピッチとロール)は、ほとんど動いていないので、外している。縦軸の数値は、ラディアンで見た角度である。0度の位置は、事前に決まっている。静止状態で、まっすぐに立って、両手をまっすぐ前に出した状態が、全ての関節が0度になっている状態である(下図を参照)。実際のモータの組み込み状況がわからなければイメージできないと思うが。
上から見ていこう。
(1)1番上の交互に動いているのは、左右の肩の、前後の揺らしである。手を振りながら歩いているのである。
(2)3番目は、肘の縦方向への回転である。ほとんど動かしていない。
(3)次の鋸の刃のような二つのデータは、膝の折りたたみである。0.2秒で1パルスの動きをして、非常に急で細かい。
(4)6番目の黄土色の上下のカーブは、右肘のRoll、人間では、大きく動く方向への変化である。これに対する左肘の動きは、下から2とか3番目にあるオレンジの曲線である。
(5)その下の鶯色とオレンジ色の水平な線は、肩の縦方向の回転と指の動きで関係ない感じだ。
(6)その下のオレンジと緑の綺麗な対照的な動きは、緑が右肘の動きで、オレンジが右の股関節の左右の動きである。
(7)その下の大きな鋸の歯のような動きは、二つの足の股関節の前後の動きである。
(8)一番下の鋸の歯型の動きは、くるぶしの動きである。
一つ気になったところは、歩行の終わり方である。なだらからに終わっていくかと思ったら、かなり唐突に動きを止めている感じである。
このアングルデータは、全て、Choregrapheのポーズデータに変換でき、それら一連のポーズをロボットに再現するモジュールをC++で作ってあるので、この歩行をほぼそのままNAOに再現させることができる。その動きは、再現するスピードを自由に変えることができるので、どこまで早くすることができるのか、さらには、早くするとき、何を調整すれば安定するのかを調べていきたい。