文章のprolog二分木化に際して、juman, knpが吐き出す語のカテゴリ情報を加えることにした。意味カテゴリにどんなものがつくかは、こちらが参考になる。ただ、juman++のものだが、jumanのものが見つからなかった。多分、同じようなものだろうと思う。
カテゴリがわかると、言葉の使い方に大きな力になる。カテゴリがばその言葉XXには、「XXに行く」という表現が成立するが、食べ物YYには「YYに行く」という表現は成り立たない。代わりに、「YYを食べる」は成り立つが、「XXを食べる」は、比喩としてしか成立しない。
逆にそれは、お笑いのボケ的には成立する。「XXを食べた」はボケであり、「そんなもの食べてうまいか!」というツッコミも成立する。
prologの宣言文(二分木)を作成するプログラムには少し手間取ったが、「羅生門」の一節は、例えば、次のような感じで変換される。
plsample(line0_7,
node(だから,
[],
node(を,
node(が,
[[下, '場所-機能'], [人, 人]],
[[雨, 抽象物], [やみ, 抽象物]]
),
node(いたと,
[待って, 待つ],
node(よりも,
云う,
node(に,
[雨, 抽象物],
node(られた,
[ふりこめ, ふりこめる],
node(が,
[[下, '場所-機能'], [人, 人]],
node(に,
node([],
node(が,
[行き, [所, '場所-施設']],
なくて
),
[途方, 抽象物]
),
node(いたと,
[くれて, くれる],
node([],
云う,
node(が,
方,
node([],
適当である,
[ ]
)
)
)
)
)
)
)
)
)
)
)
)
).
例えば、6行目に、下人がある。jumanが下人を形態素解析で、下と人に分けてしまう。そこはそれとして問題だが、下は場所であり、人は人というカテゴリに属するという情報を、prologのリストにして組み込んでいる。
名詞にカテゴリが付与されている場合は、[下, '場所-機能']のように、その表示語とカテゴリが一対になったリストになる。この場合は、'-'が間に挟まれているので、prologがAtomとして正しく処理されるようにアポストロフィ「'」で囲んである。カテゴリを持っていなければ、表示後だけになる。一方、動詞は、[待って, 待つ],のように、表示語と原型が一対になっている。原形がなかったり、表示語と原形が同じ場合は、表示語だけになる。
例えば、「下人が雨やみを待っていた」をjumanを経由してknpにかけると、次のような結果(-simple) を出してくる。
# S-ID:1 KNP:4.19-CF1.1 DATE:2019/03/17 SCORE:-21.54059
* 2D <体言>
+ 1D <体言>
下 した 下 名詞 6 普通名詞 1 * 0 * 0 "代表表記:下/した 漢字読み:訓 カテゴリ:場所-機能"
+ 4D <体言>
人 じん 人 名詞 6 普通名詞 1 * 0 * 0 "代表表記:人/じん 漢字読み:音 カテゴリ:人"
が が が 助詞 9 格助詞 1 * 0 * 0 NIL
* 2D <体言>
+ 3D <体言>
雨 あめ 雨 名詞 6 普通名詞 1 * 0 * 0 "代表表記:雨/あめ 漢字読み:訓 カテゴリ:抽象物"
+ 4D <体言>
やみ やみ やみ 名詞 6 普通名詞 1 * 0 * 0 "代表表記:闇/やみ カテゴリ:抽象物"
を を を 助詞 9 格助詞 1 * 0 * 0 NIL
* -1D <用言:動>
+ -1D <用言:動><格解析結果:ガ/人;ヲ/やみ;ニ/-;デ/-;ヨリ/-;時間/-;ノ/->
待って まって 待つ 動詞 2 * 0 子音動詞タ行 6 タ系連用テ形 14 "代表表記:待つ/まつ"
いた いた いる 接尾辞 14 動詞性接尾辞 7 母音動詞 1 タ形 10 "代表表記:いる/いる"
EOS
ここで、*から始まるものを、私は「句 phrase」と定義している。したがって、複数の「語」が「句」を作り、複数の「句」が文章を作るということである。この文章を、prolog化すると次のようになる。
%% phrases: [ 0 r1 2 ]
plsample(line0_0,
node(を,
node(が,
[[下, '場所-機能'], [人, 人]],
[[雨, 抽象物], [やみ, 抽象物]]
),
node(いた,
[待って, 待つ],
[ ]
)
)
).
最初の文章は、prologのコメントでしかなくて、以下のものが第二句をルートフレーズとして、二分木が作成されたことを示している。(この辺りは以前の記事で詳細に解説したが、少し繰り返しの説明になっている。細かく知りたい場合は、過去の記事にあたっていただきたい)
ツリーで表すと次の画像のようになる。
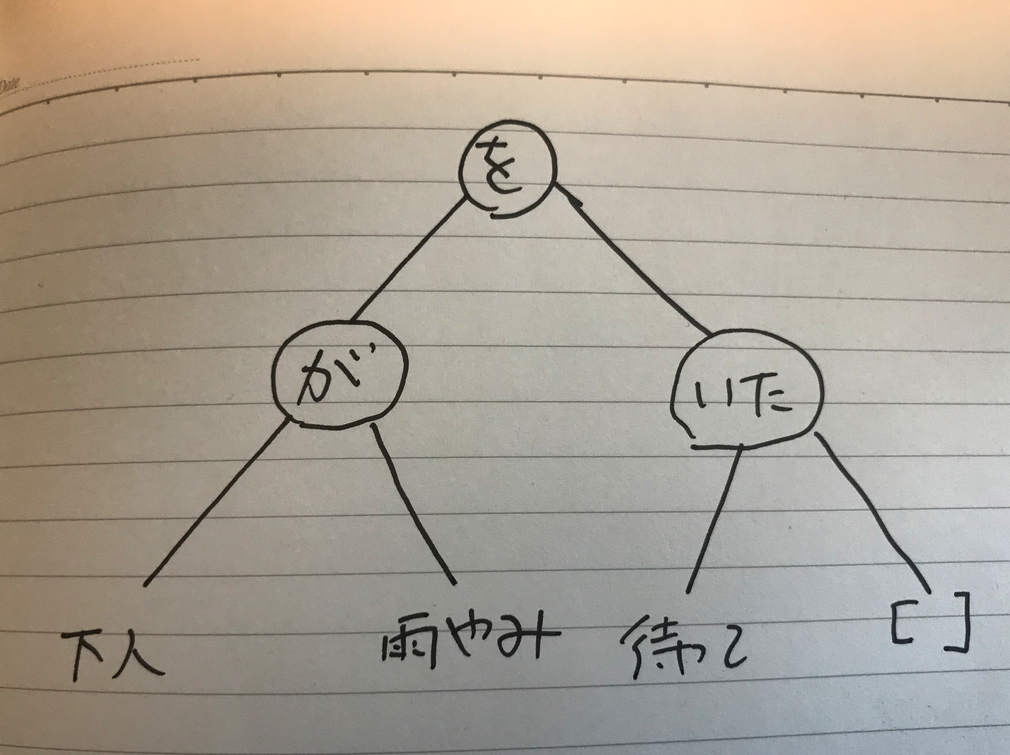
最後の語は、ここでは、空リスト [ ]になっているが、必ずしも、そうなるわけではない。この辺も、過去の記事をいていただきたい。
少し過去を振り返る回り道をしたが、その理由は、句に注目していただきたかったからだ。ここでは、最初の句は、「下人が」になる。jumanは「下」と「人」と「が」という、三つの語でこの句を構成していると形態素解析した。最初に「下」という名詞で、[下, '場所-機能']というカテゴリとのペアのリストを作成して、さらに次に、「人」という語が来たので、[人, 人]というペアリストを作成して、それを前の[下, '場所-機能']と繋げたのであるが、これをprologで処理可能なように、それらをリストとして繋げて、[[下, '場所-機能'], [人, 人]]にした。これをリストにしないと、それらが二分木の左右の葉と解釈されて、次に来る右葉にとの関係で、エラーを引き起こしてしまう。
もし、語「下」にカテゴリがなかったら、これは、カテゴリを持たない単独語となり、次いの「人」が現れた時に、結局リストは、[下, [人, 人]]と構成されることになる。
もし[[下, '場所-機能'], [人, 人]]を作成した後に、同じ句内に別のもう一つの名刺とカテゴリがあって、[菓子, '人工物-食べ物']というリストを作ったら、これらは、
[[下, '場所-機能'], [人, 人],[菓子, '人工物-食べ物'] ]
という、それまでの中に、三つ目のリストとして組み込まれるのではなく、
[[[下, '場所-機能'], [人, 人]],[菓子, '人工物-食べ物']]
と、新たに、全体を囲むリストを作って、その中に収められる。どう違うのか?ちょっと、分かりにくいが、つまり、要素が上の場合のように三つになることはなく、一つのリストの中の要素は、リストか単独語の二つの要素しかないということである。結局これも二分木になっているのである。
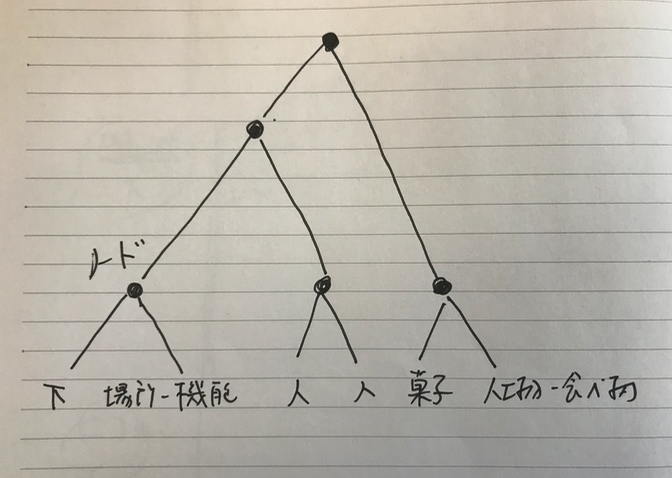
図に描くと上のようになる。