これまでのシステムを、二分木だとは考えていたが、とても特殊なものだと思っていた。しかし、前の記事までの考察を踏まえると、実は、普通の二分木であることに気付いた。
前の記事と同様に、次のような抽象的文章(あるいは、一般化された日本語文章)を考える。
句番号、リーフ語、ノード語
0, A, あ
1, B, い
2, C, う
3, D, え
4, E, お
5, F, か
6, G, き
7, H, く
この抽象的文章は次のようなものである。
「AあBいCうDえEおFかGきHく」
これをルート語を5番の句として、2番の句を接続詞として、0,1番と3,4番のサブツリーをつなげているとし、句番号のリストとすると(カンマを省略)、
[[0 1 (2) 3 4] (5) 6 7]
という表し方が可能である。全体のリストのルートは5番、サブリスト[0 1 2 3 4]のルートが2番となっている。
今この情報をもとに、再帰的にツリーを作り上げていくことを考える。このツリーは、常に左側の句番号が、右側の句番号よりも小さいことを前提にする。そして、ルートから順番に値を入れていく。
入れていく句番号については、次のようなルールで入れる。
(1)そのリストのルート句番号を最初に入れる
(2)ルートの句番号に近いものから値をとばさず順次入れる
(3)サブリストに入った時は、そのリストを上記二つのルールで先行して処理する
ツリーが作られていく様子は次のように表される。
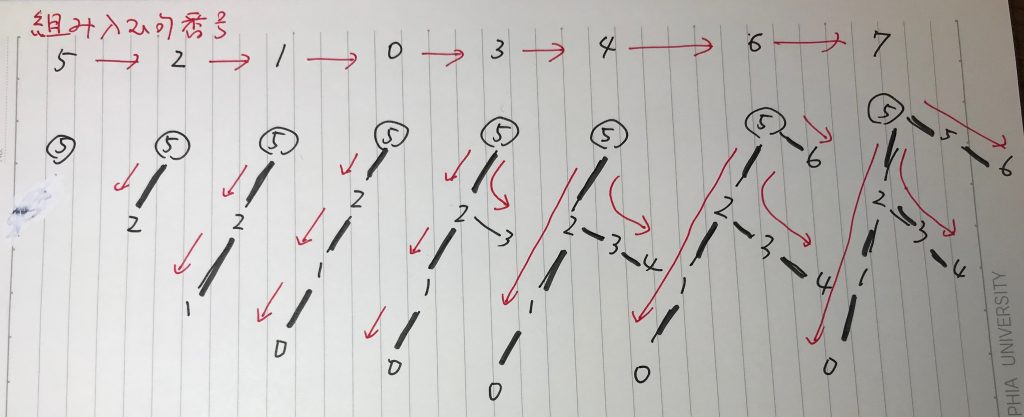
出来上がったものは、先の記事で書いた抽象的文章の二分木に他ならない。
右に接続詞があった場合も、基本的にストーリーは同じである。