現在、日本語wikipediaの50%を二分木化したが、そのデータを使って、およそのパフォーマンスがわかってきた。この段階でのファイルサイズは、3.68Gバイト。つまり、もし全てのwikipedia本文を二分木化すると7Gバイトになるということだ。
これをswi-prologで読み込ませると(ルールファイルも読み込ませたが、こちらはサイズはとても小さい)、読み込みに約30分かかる。これは、前にも予想した通りだ。そうすると、swi-prologの実行プログラムのメモリ占有量が15Gバイトくらいになる。これは確かに大きい。私のMac Proは64ギガ積んでいるので、それから見ると余裕がまだあるのだが、大きいことは間違いない。
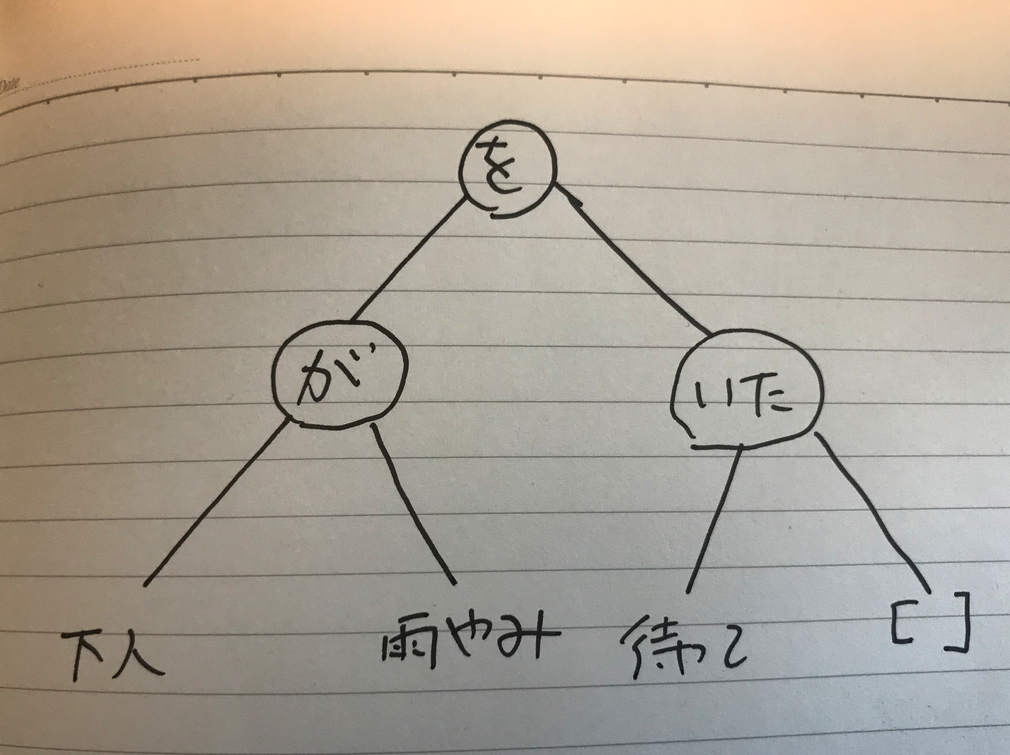
それで、例えば、「ロボット」という語を「は」という助詞付きで検索させると、次のような感じの結果を303行出力する。途中省略している。
1 ?- left(ロボット,は). wiki_1_line_3385_2: ロボットは/いわゆる脳を持た関わらないにもずまるで/生きているかのように行動する// wiki_1_line_28713_0: ロボットはそれまでのリアルロボットアニメのデザインとは一線を画した/斬新な/ものであった/ wiki_2_line_62217_1: ロボットはボートに4体の演奏人形が乗った/もので宮廷のパーティで池に浮かべて/音楽を演奏したと言われている/ 4の演奏人形が乗った/もので宮廷のパーティで池に浮かべて/音楽を演奏したと言われている/ wiki_3_line_31429_2: ロボットは胸部から放つ/ビームのシグナルフラッシュ// wiki_3_line_44126_0: ロボットは独自に/考案した/ものであると説明していた/ wiki_3_line_69544_0: ロボットは鉄神/てつじんと呼ばれサイズの大きい/順に/G~Aクラスの等級が付けられている/ G~Aの等級が付けられている/ ・・・・・・ ・・・・・・ ・・・・・・ ・・・・・・ wiki_508_line_38121_0: ロボットは補高部を取り除いた/構成となっている/ wiki_510_line_87051_1: ロボットはアッセイプレートを移動させたりサンプルおよび試薬を添加/混合/インキュベーションをしたりして最終的に検出のための場所に動かす/ことをする// wiki_517_line_78404_1: ロボットはスーパー戦隊シリーズとしてはパワーレンジャーも含めても初の試みとなる// wiki_526_line_43826_0: ロボットは2体/いて/青が太郎/赤が花子という/名前がつけられている/ 2/いて/青が太郎/赤が花子という/名前がつけられている/ wiki_532_line_38273_2: ロボットは据え置き型が多かったがFetchは障害物などを避けながら自律的に移動できる/特徴がある// wiki_532_line_38273_4: ロボットは長さが約60cm/7自由度を持ち/6kgまでの商品をピックアップ/可能// 7自由を持ち/6kgまでの商品をピックアップ/可能// wiki_539_line_25554_0: ロボットは人間の腕に似た/働きをする/メカニカルアームの一種であり通常はプログラミング可能である// wiki_539_line_25556_1: ロボットは溶接や組み立て中の部品の回転や設置などのいろいろな/タスクを行う// wiki_539_line_25567_0: ロボットは使われてきた/
この303行を出力するのは約1分で、1秒あたり5行出力していることになり、検索は、超高速だ。
読み込んだ日本語wikipediaの二分木をswi-prologのqsave_programで保存する。保存は、数分しか狩らなかったと思う。ここだけは計っていない。何しろ、短時間で保存できたのだ。保存した結果のバイナリファイルは、2.5Gバイトだった。
これは、実行形式になっているので、そのまま(swi-prologを開始することなく)実行できる。コマンドを打って、prologのプロンプトが出るまで、40秒しかかからなかった!!超早い。巨大なデータも、一旦、バイナリ形式(swi-prologの内部表現形式)に変換して保存すると、超高速で実行可能な状況になるのだ。
十分実用範囲だ。