今日は1日、時間が取れたので、午後ずっと、ロボットのプログラミングをやっていた。なんとか、ロボットにお題を問いかけて、そのお題をWikipediaにアクセスして調べさせて、主要な答えを返すというところまでやらせたが、まだまだ不安定で、実用性が低い。他の言葉は、ランダムにボケさせただけ。
不安定さについては、また別に書こうと思う。
sallybotというシステム名にした
この間のシステムを、現在のマイロボットの名前と同じ、sallybotと呼ぶことにした。
python からmysqlをつかうためのMySQLdbのインストール
virtualenvで、Google cloud関係のシステムを動かしているので、対話ボット関係のためにインストールしたモジュールが読み込めなくなっていたので、その環境でもう一度インストールしようと思った。だいたいできたのに、MySQLdbだけが、忘れていて、改めて以下のコマンドでインストールしたことをここに記録しておく。
(env) toyo-book:sally washida$ pip install MySQL-python
Google Cloud APIのストリーミングを継続して使う
Google Cloud APIのストリーミング音声認識を、ロボットとの継続した対話に使おうとすると、60秒の制限があって、それ以上使えずに、例外が発生してアボートしてしまう。これでは使えない。
そこで、gracefull(優美)に一つの会話を終了させながら、次の会話に入っていくということがどうしても必要になる。その基本的なやり方を以下に記しておく。
(1)ロボットからの音声データのストリーミング入力は、それとして生かしておくという戦略。
(2)Google Cloudからは、送られたーデータの解析結果が中間的に、最終的にの二つのバージョンで送られて来るが、最終バージョンが送られて来たら、それを一旦出力(エコーロボットとしてロボットに喋らせる、あるいは、人間入力の言葉を解析して応答を用意したりして)
(3)これで例外を発生させずに終わるが、これだと一回の聞き取りしかできなくなってしまう。そこで、
requests = request_stream(buffered_audio_data, RATE)
のスレッドの作成から、再度はじめ直す必要がある。そこでここからを関数化して、先の終了後に、再帰的にこの関数を呼び出すようにすればいい。すると、また60秒制限の新しいスレッドが立ち上がる。無限続けるのは良くないので、いったい何度ロボットやり取りするかを事前に与えておいて、その回数の会話をしたら全てを終了させるようにすれば良い。
(4)一つ問題は、(2)で、会話が入れば、一つのスレッドはグレースフルに終わるが、無言の時間が続くと終わるタイミングを逃して例外を発生させてしまう。そこで、60秒以内の一定時間無言が続くと、一旦gracefullに終わらせる。
そこで、次のようなタイマーイベントを、先に分離した関数部分の中に置いておく、
###############
def stopAPI():
print "ループを止めます"
recognize_stream.cancel()
#ここまでが関数、以下でタイマーでこのハンドラーを呼び出す
t=threading.Timer(MAX_SILENT_LENGTH,stopAPI)
t.start()
###############
関数の中にstopAPIという関数を定義して、MAX_SILENT_LENGTHの秒数が経過すると、
recognize_stream.cancel()
というイベントを発生させる。すると、CANCELLという例外が発生して、綺麗に終わるように例外処理手続きが組み込まれているのでうまくいく。そしてこの例外処理が終わった後、さいど、先に作成した関数、request_streamから始める関数をスタートさせれば良い。
これで、指定回数の会話が終わるまで、継続的にGoogle Cloud APIでストリーミング処理を続けることができる。
これで、人工無脳の会話ボットと、ロボットNAO、そしてGoogle Cloud APIの三つをつなぐ準備が80%ほど、整った。
ibotのライブラリにタイマーコマンドを加える
ロボットと何かパフォーマンスをやっているときに、尺が気になる。時間切れで失格ということが実際にあるからだ。そこで、対話システム用のコマンドに、タイマーコマンドを作成した。
トピックファイルの中に、
$wscom_starttimer_1=タイマー秒数
をいれると、それが実行された段階で、指定秒数のタイマーがスタートする。時間が来ると割り込みイベントが発生するので、それを、トピックファイルのイベント関数で、たとえば、
u:(e:TIMEOUT) 時間が来ました
のように、しておけばよい。
途中でタイマーを止める時は、
$wscom_stoptimer_1=1
をトピックファイルに埋め込んでおけば良い。
人工無脳の会話ボットとGoogle Cloud APIの接合
「pythonプログラミングパーフェクトマスター」のマルコフ連鎖の応答部分を、WikiPediaからの情報に基づいたものにするという、ほぼ、目的どうりの人工無脳会話ボットができた。
人工無脳は、ほぼお笑いのボケの一種となる。つっこめるのだ。
一方、お題についてのWikipedia情報は、人工知能的なもので、そのギャップが笑いになる。
これをGoogle Cloud APIのスピーチシステムに接合すれば目的のものが出来上がる。
辞書をMySqlに変更したdictionary.py (2017.02.14更新)
辞書をMySqlにしたばあいのdictionary.pyは次のようになった。ただし、テンプレート型までしかいれていない。python2用であり、python3でやると不都合が起きると思う。なお、テキストブックの方は、python3用になっていた。
####################################
# -*- coding: utf-8 -*-
import MySQLdb
from analyzer import *
import re
"""
様々な辞書を処理するクラス
金城俊哉著「Pythonプログラミングパーフェクトマスター」を参照した
2017年2月12日 作成
"""
class Dictionary:
def __init__(self):
print "Dictionary を初期化します"
self.conn = MySQLdb.connect(
user='washida',
passwd='robotcomedian',
host='localhost',
db='dictionary',
charset="utf8"
)
self.c = self.conn.cursor()
# 辞書データを全て取得する
# ランダムフレーズの取得
sql = 'select * from random'
self.c.execute(sql)
self.random = [] #
print 'ランダムフレーズの取得 >> ',
count = 0
for row in self.c.fetchall():
#print 'id:', row[0], 'Phrase:', row[1], "\n"
if (row[1] != ''):
count += 1
self.random.append(row[1])
print "終了 総数 = ",str(count)
# パターンフレーズの取得
sql = 'select * from pattern'
self.c.execute(sql)
# 辞書型のインスタンスを用意
# self.pattern = {}
self.pattern = []
print 'パターンフレーズの取得 >> ',
count = 0
for row in self.c.fetchall():
# print 'id:', row[0], 'Pattern:', row[1], 'Phrase:', row[2], "\n"
if row[1] != '' and row[2] != '':
count += 1;
#self.pattern.setdefault('pattern', []).append(row[1])
#self.pattern.setdefault('phrases', []).append(row[2])
self.pattern.append({'pattern':row[1],'phrases':row[2]})
print "終了 総数 = ",str(count)
# 終了時に、データの更新が必要なpatternオブジェクト
self.update_pattern = []
# 終了時に新規追加が必要なpatternオブジェクト
self.newitem_pattern = []
# テンプレートデータの取得
print 'テンプレートフレーズの取得 >> ',
self.template = {}
sql = 'select max(nounnum) from template'
self.c.execute(sql)
#print "sql = ",sql
row = self.c.fetchone()
print '名詞最大数 = ', row[0],
count = 0
for i in range(int(row[0])):
j = i+1
sql = "select * from template where nounnum = '" + str(j) + "'"
self.c.execute(sql)
for row in self.c.fetchall():
#print 'id:', row[0], 'Nounnum:', row[1], 'Template:', row[2], "\n"
if row[1] != '' and row[2] != '':
if not row[1] in self.template:
self.template[row[1]] = []
self.template[row[1]].append(row[2])
count += 1;
print "終了 総数 = ",str(count)
# 終了時に、データの更新が必要なtemplateオブジェクト
self.update_template = []
# 終了時に新規追加が必要なtemplateオブジェクト
self.newitem_template = []
self.c.close()
self.conn.close()
def study(self, input, parts):
""" study_random()とstudy_pattern()を呼ぶ
@param input ユーザーの発言
@param parts 形態素解析結果
"""
# インプット文字列末尾の改行は取り除いておく
input = input.rstrip('\n')
# インプット文字列と解析結果を引数に、パターン辞書の登録メソッドを呼ぶ
self.study_pattern(input, parts)
# テンプレート辞書の登録メソッドを呼ぶ
self.study_template(parts)
def study_pattern(self, input, parts):
""" ユーザーの発言を学習する
@param input インプット文字列
@param parts 形態素解析の結果(リスト)
"""
print "学習を開始します"
# 多重リストの要素を2つのパラメーターに取り出す
for word, part in parts:
# analyzerのkeyword_check()関数による名詞チェックが
# Trueの場合
if (keyword_check(part)):
print "キーワードが存在しました!!"
depend = False # パターンオブジェクトを保持する変数
# patternリストのpattern辞書オブジェクトを反復処理
for ptn_item in self.pattern:
# インプットされた名詞が既存のパターンとマッチしたら
# patternリストからマッチしたParseItemオブジェクトを取得
if(re.search(ptn_item['pattern'], word)):
depend = ptn_item
break #マッチしたら止める
# 既存パターンとマッチしたParseItemオブジェクトから
# add_phraseを呼ぶ
if depend:
print "キーワードが既存のパターンにマッチするものでした!"
#depend.add_phrase(input) # 引数はインプット文字列
if(re.search(depend['phrases'], input)):
# すでにフレーズも含まれている場合は、なにもしない
pass
else:
# 既存のパターンに合致するが、フレーズに含まれていないものについては、フレーズに加えるだけにする
depend['phrases'] += ('|'+input)
# 終了時に更新すべきオブジェクトに位置付ける
self.update_pattern.append(depend)
else:
print "キーワードが既存のパターンにマッチしないものでした!"
# 既存パターンに存在しない名詞であれば
# 新規のParseItemオブジェクトを
# patternリストに追加
newitem = {'pattern':word, 'phrases':input}
self.pattern.append(newitem)
# 終了時に新規追加しなければならない
self.newitem_pattern.append(newitem)
def study_template(self, parts):
""" テンプレートを学習する
@param parts 形態素解析の結果(リスト)
"""
template = ''
count = 0
for word, part in parts:
# 名詞であるかをチェック
if (keyword_check(part)):
word = '%noun%'
count += 1
template += word
# self.templateのキーにcount(出現回数)が存在しなければ
# countをキーにして空のリストを要素として追加
if count > 0:
count = str(count)
if not count in self.template:
self.template[count] = []
self.newitem_template.append(count)
# countキーのリストにテンプレート文字列を追加
if not template in self.template[count]:
self.template[count].append(template)
self.update_template.append({'nounnum':count,'template':template})
def closeDict(self):
# データベースへの変更を保存、あれば
self.conn = MySQLdb.connect(
user='washida',
passwd='robotcomedian',
host='localhost',
db='dictionary',
charset="utf8"
)
self.c = self.conn.cursor()
# 辞書データを更新する
print "辞書データベースを更新します"
for item in self.update_pattern:
#
sql = "update pattern set phrases = '" + item['phrases'] + "' where pattern = '" + item['pattern'] + "'"
print "sql = ",sql
self.c.execute(sql)
for item in self.newitem_pattern:
#
sql = "insert into pattern (pattern, phrases) values ('" + item['pattern'] + "', '" + item['phrases'] + "')"
print "sql = ",sql
self.c.execute(sql)
for item in self.update_template:
# アップデートすべきtemplateだけがはいっているので、全部加える
sql = "insert into template (nounnum, template) values ('" + item['nounnum'] + "', '" + item['template'] + "')"
print "sql = ",sql
self.c.execute(sql)
for num in self.newitem_template:
# 新規なので、全部加える 新規の番号の文字列だけが入っている
for tmp in self.template[num]:
sql = "insert into template (nounnum, template) values ('" + num + "', '" + tmp + "')"
print "sql = ",sql
self.c.execute(sql)
self.conn.commit()
#データベースを閉じる
self.c.close()
self.conn.close()
あるPythonの本
「Python プログラミングパーフェクトマスター」という本を購入して、記載のプログラムを動かしている。辞書のところを、MySqlのデータベースに変換、プログラムを一部改定しながら動かし続け、形態素解析のところまできた。実に面白い本だ。結構たくさんのプログラミング関係の本を買ってきたが、こんなにドキドキする本には滅多に会わない。最後まで、きちんと追っていきたい。
ただ、だからと言ってこの本を勧めているわけではない。プログラミング本の場合、読者が求めているものと一致するかどうかが問題であって、合わないと、やたら問題だけが目につくというパターンがあるからだ。本を買う行為は常に自己責任だ。不安な本は買わなけれりゃいいし、買ってから本に八つ当たりするのは馬鹿げている。
次のような変更を加える。
(1)当面、感情の要素には興味ないので、全て削除する。感情はもっと違う入れ方があると思っている。
(2)dictionaryのpatternオブジェクトを、
self.pattern = {}
for row in c.fetchall():
if row[1] != '' and row[2] != '':
self.pattern.setdefault('pattern', []).append(row[1])
self.pattern.setdefault('phrases', []).append(row[2])
のような入れ方から
self.pattern = []
for row in c.fetchall():
if row[1] != '' and row[2] != '':
self.pattern.append({'pattern':row[1],'phrases':row[2]})
に変更する。
つまり、パターントフレーズのセットを辞書オブジェクトにして、pattern配列に次々に入れておくようにした。
これ以前は、patternは、それを入れた配列と、phraseを入れた配列を辞書オブジェクトにしていた。
いわば、縦にしていたものを横にしたという感じた。
(3)それにともなって、ParseItem系のクラスが全く必要なくなる。
久しぶりのJAVA
この間、でっかいTOPICファイルを二つばかり作り、そこにいろんなネタのデータを放り込んだんだけれど、大きなデータをTOPICファイルに入れるのはやや無理があると思い、それらをもう一度読み取って、MySqlのデータベースに入れようと思った。変換のためのJAVAプログラムを適当に作成しようと思って、簡単にできるはずなのだが、久しぶりにJAVAを使おうとすると、頭が戻りにくい。まあ、また、思い出し思い出しやるしかないな。
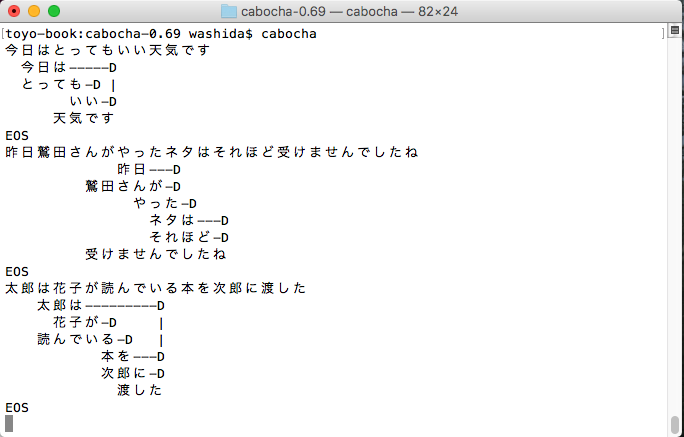
形態素解析と係り受け解析
どちらもGoogle Cloud APIでできるのだが、もうひとつ、いいものだという実感がないので、日本で開発されたMecabとCabochをインストールしてみた。以前、kuromojiも動かしたことがあるので(このサイトにも掲載してある)その辺りはある程度わかっているが、どれをどのように使うのかという迷いはある。kuromojiで形態素解析をして、その要素を使うだけで良いような気もするが、係り受け解析は必要か。
Google Cloud APIのいいところは、rootの単語を拾い出すことのような気がする。
しばらく迷う必要がある。ただ、あと2週間以内に、ロボットにちょっとしたことをさせたいと思っている。
以下は、CaboChaでの出力の画像である。