KNPをベースに、文章をprolog化するJPrologが一通りできた。
これまでも用いている芸人の定義をprolog化するとその出力は次のようになった。なお、プログラムそのものは、GitHubのJPrologレポジトリにおいてある。Cabochaバージョンは、これによって上書きされたので消去された。
(https://github.com/toyowa/JProlog)
run:
Jumanをサーバーモードでスタートさせました
KNPをサーバーモードでスタートさせました
Juman および KNP クライアントを開始しました
Juman: KILLシグナルを送りました PID = 25064
KNP: KILLシグナルを送りました PID = 25063
%%--------------------------------
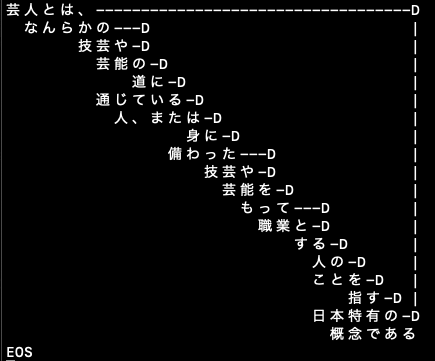
%% 「芸人とは、なんらかの技芸や芸能の道に通じている人、または身に備わった技芸や芸能をもって職業とする人のことを指す日本特有の概念である」のprolog化
%%--------------------------------
No.0 芸人,とは Kakari:16 type:D score:991
No.1 なんらか,の Kakari:3 type:D score:1000
No.2 技芸,や Kakari:3 type:P score:1000
No.3 芸能,の Kakari:4 type:D score:1000
No.4 道,に Kakari:5 type:D score:997
No.5 [通じて, 通じる],いる Kakari:6 type:D score:400
No.6 人,または Kakari:14 type:P score:1100
No.7 身,に Kakari:8 type:D score:997
No.8 [備わった, 備わる],[] Kakari:10 type:D score:-1
No.9 技芸,や Kakari:10 type:P score:1000
No.10 芸能,を Kakari:11 type:D score:1000
No.11 [もって, もつ],[] Kakari:13 type:D score:-1
No.12 職業,と Kakari:13 type:D score:988
No.13 する,[] Kakari:14 type:D score:-1
No.14 人,の Kakari:15 type:D score:1000
No.15 こと,を Kakari:16 type:D score:1000
No.16 指す,[] Kakari:19 type:D score:-1
No.17 日本,[] Kakari:18 type:D score:-1
No.18 特有の,[] Kakari:19 type:D score:-1
No.19 概念,である Kakari:-1 type: score:400
%% フレーズ番号リストのトークン = [ r0 [ 1 2 3 4 5 r6 [ 7 8 r9 10 11 12 13 ] 14 15 ] 16 17 18 19 ]
%% Prolog宣言
pl001(a01,
node(とは,
芸人,
node(または,
node(いる,
node(に,
node(の,
node(や,
node(の,
なんらか,
技芸
),
芸能
),
道
),
[通じて, 通じる]
),
人
),
node(や,
node([],
node(に,
身,
[備わった, 備わる]
),
技芸
),
node(を,
芸能,
node([],
[もって, もつ],
node(と,
職業,
node([],
する,
node(の,
人,
node(を,
こと,
node([],
指す,
node([],
日本,
node([],
特有の,
node(である,
概念,
[ ]
)
)
)
)
)
)
)
)
)
)
)
)
)
).
後半のprologの宣言文は、swiprologで問題なく解釈されている。listingすると、次のようになっている。
pl001(a01, node(とは, 芸人, node(または, node(いる, node(に, node(の, node(や, node(の, なんらか, 技芸), 芸能), 道), [通じて, 通じる]), 人), node(や, node([], node(に, 身, [備わった, 備わる]), 技芸), node(を, 芸能, node([], [もって, もつ], node(と, 職業, node([], する, node(の, 人, node(を, こと, node([], 指す, node([], 日本, node([], 特有の, node(である, 概念, [])))))))))))))).
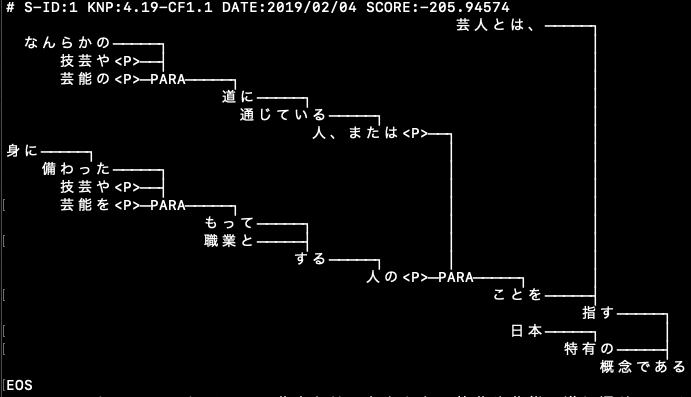
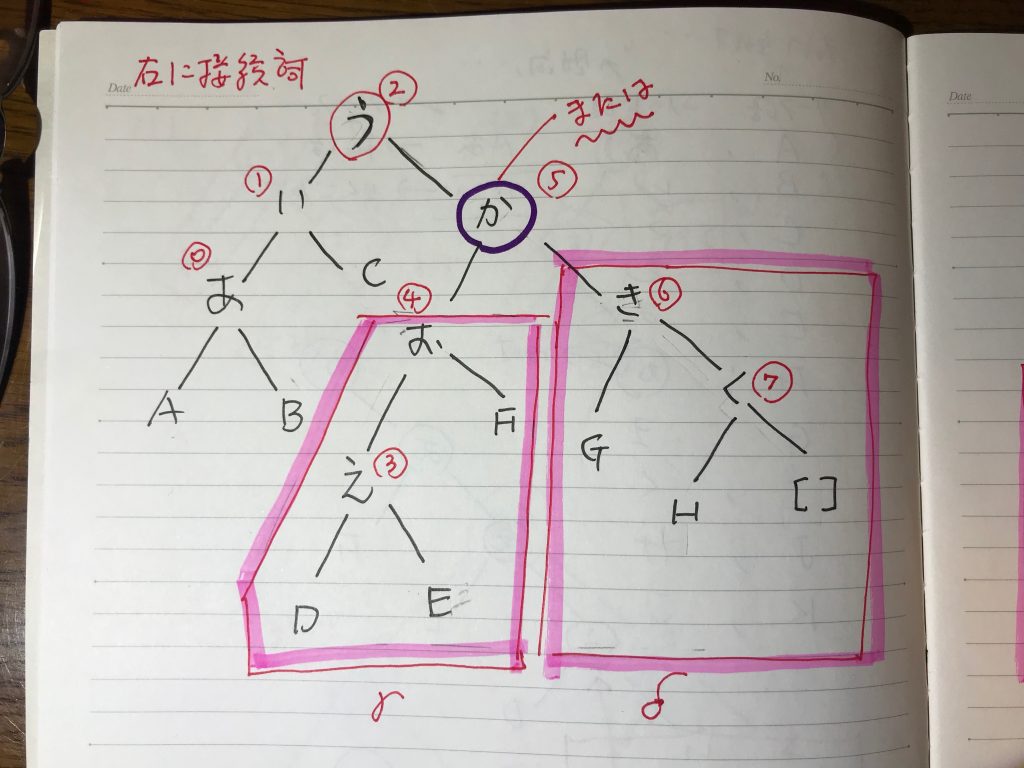
KNPの係り受け解析をもとにしている。「フレーズ番号リストのトークン」のところにある、リスト構造がわかりやすい。
(1)「芸人とは」の主語は、係り受け解析の結果から、そこでの第16番目の句にかかっているので、そこは、うまくとらえている。
(2)または、という接続詞が大きな構造を作っているが、それが「人」にかかっているところは、まあまあ、とらえている。
この後のものは、特に、cabochaでは、うまくとらえられなかったので、大いに良い。が、
「wikipedia「芸人」の定義とprolog(3)リスト処理追加」
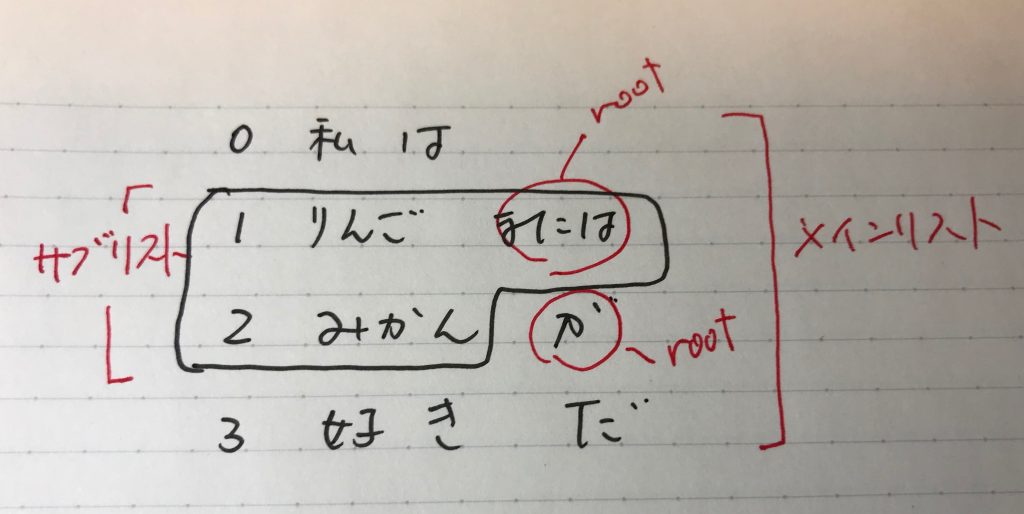
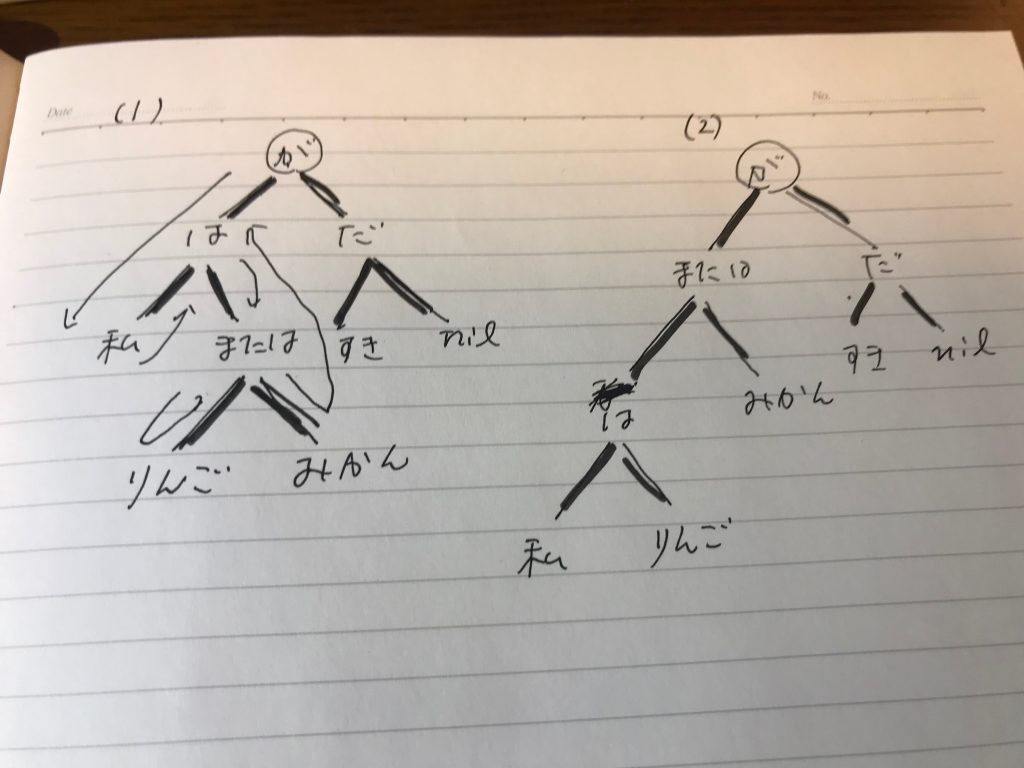
の記事で示した、私の直感的なものよりも、何かしらもう一つ劣っている感は否めない。形態素解析ツールがmecabからjumanに変わったので、ノード語とリーフ語で、取れてないものが増えて空リスト [ ]になっているが、これは修正可能で、また、大きな問題でもない。
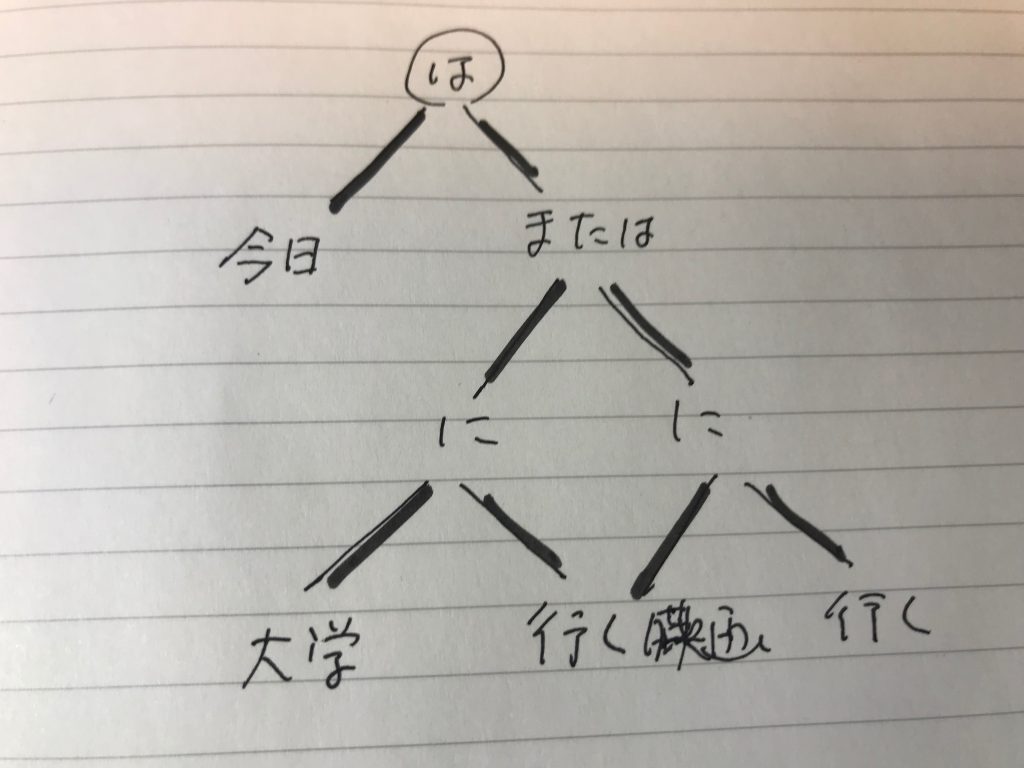
KNPの解説サイトで使われていた、「私は傘を買い、そして家に帰った」という文章を解析して、出力した結果は次のようなものである。
%%--------------------------------
%% 「私は傘を買い、そして家に帰った。」のprolog化
%%--------------------------------
No.0 私,は Kakari:4 type:D score:991
No.1 傘,を Kakari:2 type:D score:1000
No.2 [買い, 買う],そして Kakari:4 type:P score:1100
No.3 家,に Kakari:4 type:D score:997
No.4 [帰った, 帰る],[] Kakari:-1 type: score:-1
%% フレーズ番号リストのトークン = [ r0 [ 1 r2 3 ] 4 ]
%% Prolog宣言
pl001(a01,
node(は,
私,
node(そして,
node(を,
傘,
[買い, 買う]
),
node(に,
家,
node([],
[帰った, 帰る],
[ ]
)
)
)
)
).
「私は」が二つの文節にかかっている状況は捉えている。KNPの構文解析が踏まえられている。
全体として、もう少し調整する必要がある。