先のいくつかの記事で示しているように、ロボットが知識的文章を短く語る時に、削除した語を繋ぐ助詞をAI的に選択させようとしている。(体言1:名詞・動詞)+(助詞1:助詞・助動詞)+(体言2:名詞・動詞)+(助詞2:助詞・助動詞)の語の並びの中で、体言1、体言2、助詞2が与えられた時に適切な、助詞1を選択させたい。これができれば、うまく、文章を短くできるだろうということである。
そこで、この並びを、日本語wikipediaの前文から拾い出して、それを元に、ディープラーニング用の学習データを作ろうということである。
4語対は、6千万個取れて、語は、word2vecのウェイトベクトルであらわすのだが、そのベクトルを取れる語は、さらに半分以下になってしまう。また、助詞、助動詞部分のパーターンがとてつもなく大きくなってしまう。「の」とか「を」などはたくさんあるが、全体で1回しか現れないようなものも拾ってしまう。これは、広い方のアルゴリズムにも依存するのだが。
そこで、いったいどのような助詞、助動詞が、どのような頻度で現れているのかを調べてみた。
まず、助詞2(ニューラルネットの入力になる)は次のようになっている。
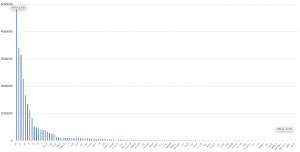
の 4848543 を 3418017 に 3153274 が 2271523 は 1676994 と 1359190 で 1134953 た 833487 な 515517 から 481586 や 449712 も 403445 て 391692 である 384000 として 321609 ている 278220 には 264654 では 242007 ていた 141653 によって 117531 であり 109701 により 109549 であった 107166 による 101919 へ 97715 でも 97698 との 95020 という 95008 まで 94623 への 88007 にも 87645 ない 80116 での 77605 たが 71719 だった 71462 など 69269 ており 69104 だ 68336 ず 64151 などの 62250 より 56385 とは 53537 において 50758 たと 47488 からの 46761 における 45079 について 38801 ば 34365 たり 33421 に対して 32896 なかった 32558 はと 31786 としては 31599 か 31034 に対する 30519 であると 30483 としての 30440 うと 30412 とも 29750 とともに 29742 ていたが 29645 だが 29500 などを 28746 までの 28607 ながら 27353 と共に 26439 へと 25588 に関する 25518 だと 25209 よりも 24233 であるが 24219 などが 23941 ではなく 23687 については 23225 であったが 21177 ているが 20375 にて 20046 てきた 19284 でいる 19168 からは 19166 ても 18992 ていない 18033 などで 17049 に対し 16993 といった 16725 だったが 16552 をと 16238 ていく 15419 などに 15401 ていると 15107 てしまう 14659 までに 14412 にと 14395 においては 13755 でいた 13566 ずに 12898 のみ 12697 なく 12433 たものの 12417 にかけて 12292
明らかに、代表的助詞型を圧倒している。だから、全部を対象にすることはない。だいたい、上位128個くらいの使い方がわかればそれでいいのではないかと思う。入力に関しては次のようになっている。
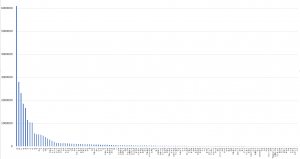
の 6087401 は 2794515 に 2311801 を 1850357 が 1667993 で 1144968 と 1039936 た 1026311 な 563759 や 531865 から 515033 て 502233 には 461876 では 405320 も 340662 である 297177 として 239221 ている 200314 という 145218 であり 141251 ていた 140480 との 135622 により 135543 による 124273 への 116794 での 114556 たが 110351 によって 100663 まで 99795 などの 99002 ており 98666 など 95691 でも 91841 ず 91712 とは 87425 であった 78465 ない 76015 にも 73529 より 69404 だ 67224 において 65830 からの 63813 における 59617 だった 59331 ば 53503 へ 50134 としての 44902 に対する 40913 に対して 40079 だが 39554 としては 38818 に関する 37624 について 37003 ていたが 36863 までの 35317 とともに 33629 からは 33043 ながら 32942 たり 31465 であるが 31366 については 30835 と共に 30434 か 28826 はと 28675 ではなく 27939 なかった 27507 といった 26896 などを 25960 に対し 25781 であったが 25642 よりも 24764 においては 24509 ているが 24095 ても 22715 にかけて 22410 にて 22061 とも 20988 だったが 20078 てきた 18660 までは 15710 はの 15630 などで 15530 たものの 15429 などが 15169 うと 14569 へと 14314 までに 14160 にとって 13547 ていない 13388 たという 13324 でいる 12949 ずに 12844 についての 12823 のの 12695 でいた 12154 ので 12077 ほど 11709 のみ 11541 であると 11315 だと 11167 はという 11122 がと 11042 をと 11024 ていく 10883 てしまう 10794 などに 10719 においても 10605 にと 10454 を通じて 10373 たと 9804 だけでなく 9448 ての 9116 しか 9065 にの 9027 によっては 8952 かの 8682 であるという 8620 に関しては 8216 てしまった 8172 ほどの 8126 ていて 8058 はなく 8000 からも 7909 ては 7779 てくる 7631 てから 7518 にという 7329 つつ 7309
上位グループの順序は微妙に変わっている。助詞の位置が影響しているのだ。が、上位グループのメンバーはあまり変わらない。