「芸人」の定義の文書でもでてきた接続詞について、もう少し調べることがあると思った。
「私はりんごまたはみかんが好きだ」の構文解析結果は次のようになる。両方好きなのか、どちらかが好きなのかはっきりわからない曖昧な文章だが、そこは問題にせずに「または」がどうなるかを見る。
* 0 3D 0/1 -2.400531
私 名詞,代名詞,一般,*,*,*,私,ワタシ,ワタシ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
* 1 2D 1/1 0.754827
りんご 名詞,一般,*,*,*,*,りんご,リンゴ,リンゴ
または 接続詞,*,*,*,*,*,または,マタハ,マタワ
* 2 3D 0/1 -2.400531
みかん 名詞,一般,*,*,*,*,みかん,ミカン,ミカン
が 助詞,格助詞,一般,*,*,*,が,ガ,ガ
* 3 -1D 0/1 0.000000
好き 名詞,形容動詞語幹,*,*,*,*,好き,スキ,スキ
だ 助動詞,*,*,*,特殊・ダ,基本形,だ,ダ,ダ
EOS
こうなると、「が」をルートにすると、次のようにprolog化する。
conjunction1(
node(が,
node(は,
私,
node(または,
りんご,
みかん
)
),
%% 次のnodeの代わりに単に「好きだ」としてもいい
node(だ,
好き,
nil
)
)
).
接続詞「または」が、助詞と同じような使われ方になる。また、右端の「好きだ」については助動詞「だ」を独立させて、上記のように"node"にしたが、それ自体を一つのatomとして扱っても良い。どちらでもあまり知識化という点では大した問題ではないのだ。
ただし、これにはもう一つのバージョンがありうる。prologではなく、次の図を見ていただきたい。
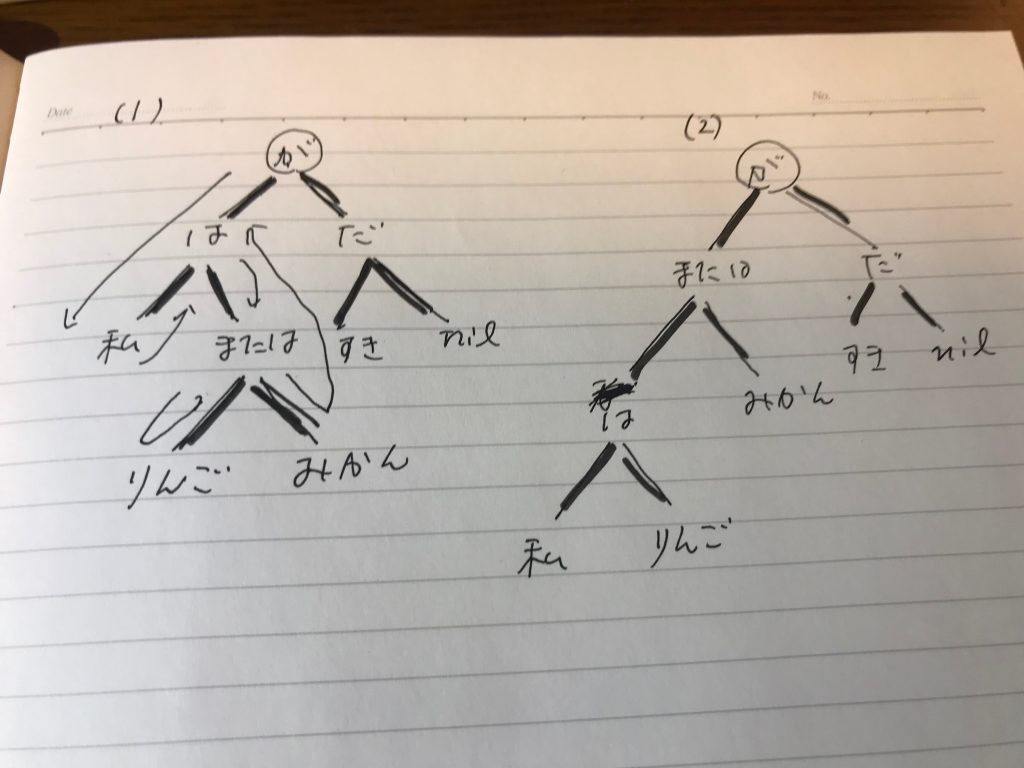
(1)が先に述べたものだが、(2)の場合もありうるのである。しかしこちらは、独立した「私はりんご」というフレーズに知識的内容がない上に、「または」が持っている並列作用が消えてしまって、りんごとみかんが切り離されてしまっている。
つまり、こうした接続詞は、演算で言えば掛け算のように足し算などから比べて高い優先順位で処理しなければならなくなるということである。ただし、こうした優先度が高くても、左右どちらかの項が、演算でいう、括弧に入った状態だと、そちらの中を先に処理するということがでて切るので、そのあたりの見極めがどうなるかが難しい。
また、この文章を「私はりんごかみかんが好きだ」という、「または」を「か」に置き換えてもほとんど同じ意味になる。この場合の「か」は、並立助詞といって、接続詞とほぼ同じ機能を持つ。ただ、cabochaは形態素解析で「か」が並立助詞として明確化せず品詞2で「副助詞/並立助詞/終助詞」と出してきて、そのどれかだよ、みたいな書き方しかしないので、困ったものだ。文中に出てくるこうした「か」は、並立助詞を疑う必要がある。
接続詞の優先性が保留される例として、「今日は大学に行く、または映画に行く」を解析する。構文解析結果は次のようになる。
* 0 5D 0/1 -1.000291
今日 名詞,副詞可能,*,*,*,*,今日,キョウ,キョー
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
* 1 2D 0/1 2.454284
大学 名詞,一般,*,*,*,*,大学,ダイガク,ダイガク
に 助詞,格助詞,一般,*,*,*,に,ニ,ニ
* 2 5D 0/0 -1.000291
行く 動詞,自立,*,*,五段・カ行促音便,基本形,行く,イク,イク
、 記号,読点,*,*,*,*,、,、,、
* 3 5D 0/0 -1.000291
または 接続詞,*,*,*,*,*,でなければ,デナケレバ,デナケレバ
* 4 5D 0/1 -1.000291
映画 名詞,一般,*,*,*,*,映画,エイガ,エイガ
に 助詞,格助詞,一般,*,*,*,に,ニ,ニ
* 5 -1D 0/0 0.000000
行く 動詞,自立,*,*,五段・カ行促音便,基本形,行く,イク,イク
EOS
係り受け解析は、ほとんど失敗しているようにも見える。頼りにならない、困った、がまたそれは後で考える。
二分技の図を見てみよう。
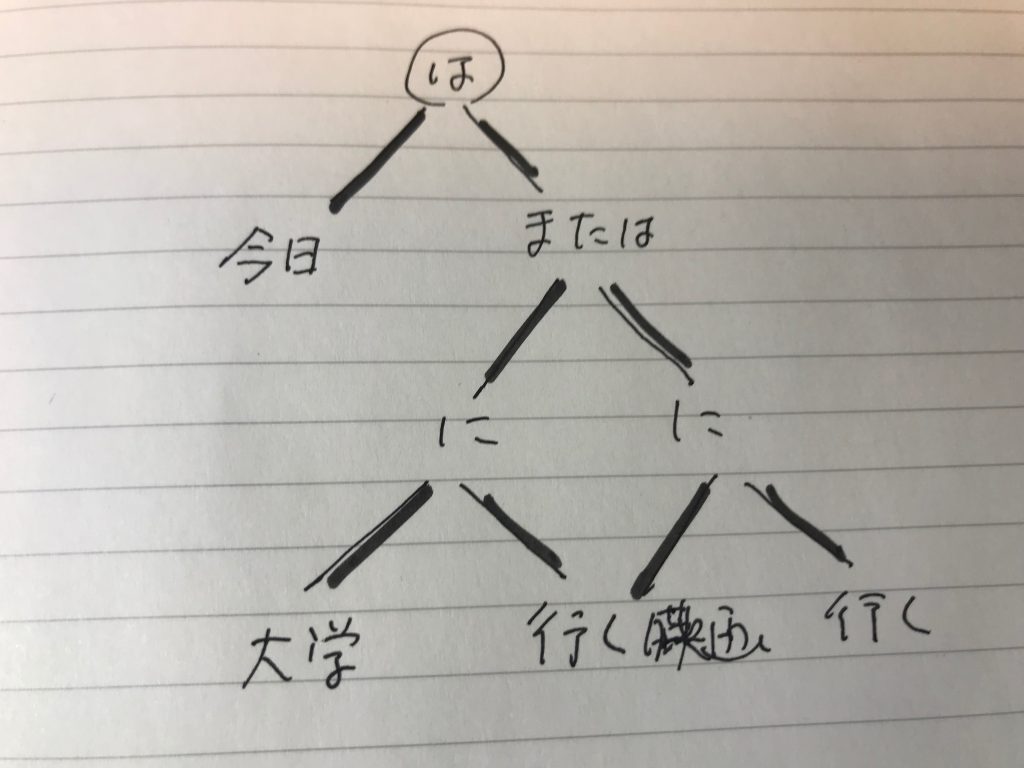
優先性をただ尊重すると、「いく、でなければ、映画」になるが、ほとんど意味を持たない関係性であるから、図のように「大学に行く」というノードと「映画に行く」というノードを並立させることが、この「でなければ」の機能なのである。どうやってこれを読み取るかが問題である。
二つのノードが一つのノードからぶら下がっている構造は、今まで出てこなかった。なぜか。一つの句の中にある助詞なり助動詞は、同じくの中に名詞化同士が必ず存在したからだ。ところが、cabochaの出力を見てもわかるように、この場合の接続詞の句の中には、名詞も動詞もない。だから、前のフレーズまでもと、後のフレーズを自分の中に取り込むことができるのである。
prolog化すると次のようになる。
conjunction2(
node(は,
node(または,
node(に,
大学,
行く
),
node(に,
映画,
行く
)
),
今日
)
).
「または」ノードのの中に二つの子ノードが含まれていることがわかるだろう。
このように見ると、接続詞というのがとても重要な役割を果たすことがわかるのだ。