物事の最中ではあるが、ここで、改めて自然言語を二分木で考えることの意味を確認しておく。
数値的二分木の意義は、よく言われるように、二分木の中に大小が秩序良く収まることであろう。例えば、私が最も参考にしたサイトの一つは次のものである。
二分木を構成していくプロセス、要素を削除する、あるいは検索、そして大小の流れの表示など、一貫して簡便に良く表現できる。
自然言語の二分木が似ているのは、数値の場合の大小の流れが、自然言語の場合、文章が一つの流れになっていることである。例えば、先の記事で使った簡単な文章、
「ロボットとともに人工知能も注目された」
この文章は、右から左に言葉が流れている。数値が、小さいものから大きなものの順に流れている、などの場合と同様である。
形態素解析の場合は、この自然言語を、「名詞」「動詞」「助詞」「形容詞」「副詞」などの多くのカテゴリで、単語の品詞を確定し、解析する。しかし、こうした単語の特徴を、二分木の場合「ノード値」「左葉」「右葉」三種類、あるいは空文字も入れて、せいぜい四種類の分類で、文章を解析しようというものである。
この二分木的形態素解析は、通常の自然言語の形態素解析と必ずしも対応させる必要はない。もちろん、厳密に対応させてもいいのだが、そうする必要はない。
ある言葉が、左の葉に来ることも右の葉に来ることもある。ノード値だけは、体言や用言を繋げる役割を果たす言葉に限定している。ただ、それも厳密なものではない。前の記事でも書いたように「ともに」という副詞は葉の言葉になることもあれば、「とともに」のようにノード値に組み込まれることもある。
なぜ、このような曖昧さが許されるのか。それは、形態素解析が、十分少ない文章のサンプルでも、きちんと合理的な判断を下すことが求められるのに対して、二分木的自然言語解析では、はなから、大量のデータを扱うことを前提にするからである。大量のデータの中には、いろいろありうる。いろいろあっても、いろいろあるからこそ、そこに新たな規則が、確率的なものかもしれないし、もっと神経回路のような曖昧さのあるルールかもしれないが、何れにしても、何らかの実際的ルールが見えてくればいいと考えるのである。
自然言語解析、我々は、あまりに古典的な解析方法に縛られすぎたのだ。コンピュータのCPUの処理能力がとてつもなく発達したこの時代の自然言語解析は、もっと違ったものであるべきだし、そうしたコンピュータの進化に適合的な解析手法が二分木なのである。
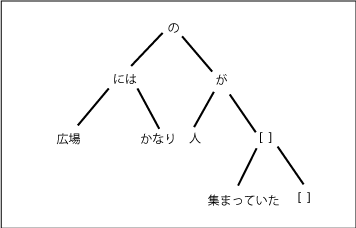 この場合、「かなり」が副詞で、右の葉に入っていて、不自然さはない。
この場合、「かなり」が副詞で、右の葉に入っていて、不自然さはない。