次の疑問文生成は、「どんな」あるいは「どのような」という疑問文である。例えば、「アトムはロボットです」を疑問文にすると「アトムはどんなロボットですか」ということになる。
この「どんな」が生成できれば、他も「なんで、なんの、なぜ、どの、どうして、どんなふうに」などの多くの疑問詞がほぼ同様の操作で生成可能になる。
まず、前にも示したと思うが、「アトムはロボットです」をシステムで二分木を生成すると次のようになる。
%% phrases: [ r0 1 ]
testdoc(testline_0_0,
node(は,
[アトム, 'S:普/C:自然物/D:科学・技術'],
node(です,
[ロボット, 'S:普/C:人工物-その他/D:科学・技術'],
[ ]
)
)
).
最初の行は、システムが生成するもので、コメント文となり、次は、生成二分木のインデクスで、他が二分木の実体である。
次に「アトムはどんなロボットですか」を二分木化すると次のようになる。
%% phrases: [ 0 1 r2 ]
testdoc(testline_0_0,
node(ですか,
node([],
node(は,
[アトム, 'S:普/C:自然物/D:科学・技術'],
どんな
),
[ロボット, 'S:普/C:人工物-その他/D:科学・技術']
),
[ ]
)
).
ちょっと、基本構造が違っている。上の二つの二分木を図で示すと次のようになる。
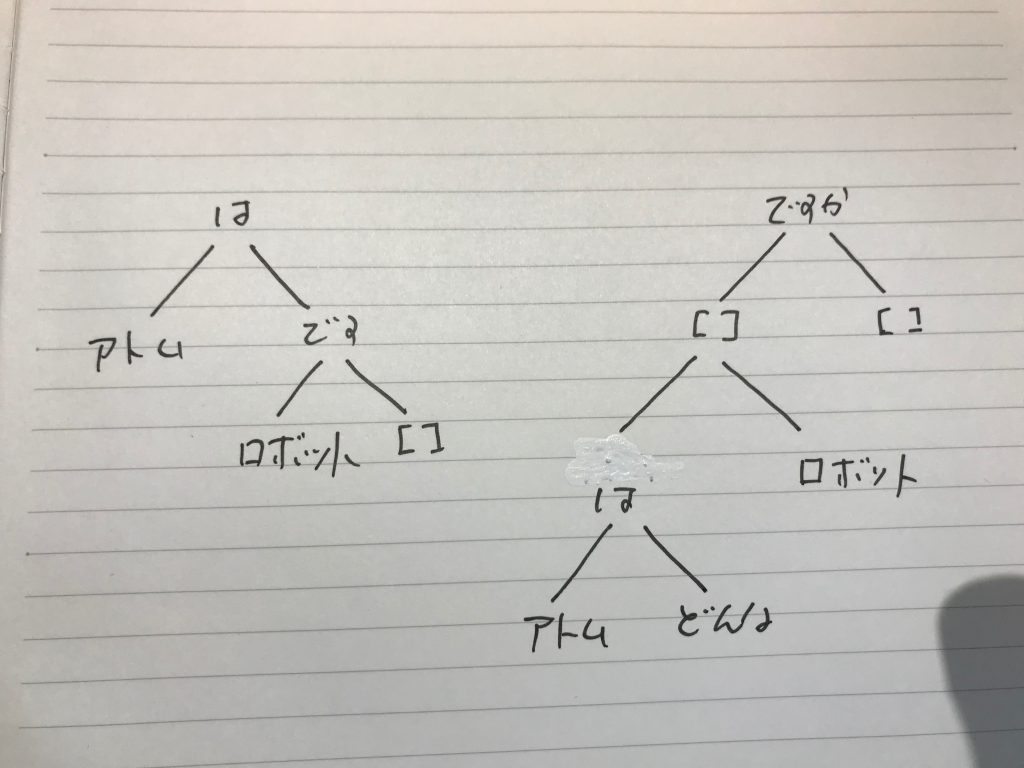
左が平常文であり右が疑問文だ。違いは、rootノードの違いである。先のシステム出力のコメント文、%% phrases:の右側に書いたものが、二分木のリストで、rのついた番号のものをルートフレーズとしているということである。
フレーズは、名詞や動詞などの単独で意味を持つ語と助詞などの付随語のペアからなっていて、システムは、いくつかの判断基準を複合させて、ルートフレーズを確定する。また、ときには、フレーズリストをネストさせて、それぞれのリストごとにルートフレーズを決定し、二分木の形を決めている。この辺りのことは、こちらなどを参照してください。
「どんな」疑問文も、ルートの違いによって、色々ありうるということである。例えば、左の構造を基本にしながら「どんな」疑問文を生成すると、次の図のような場合もありうる。
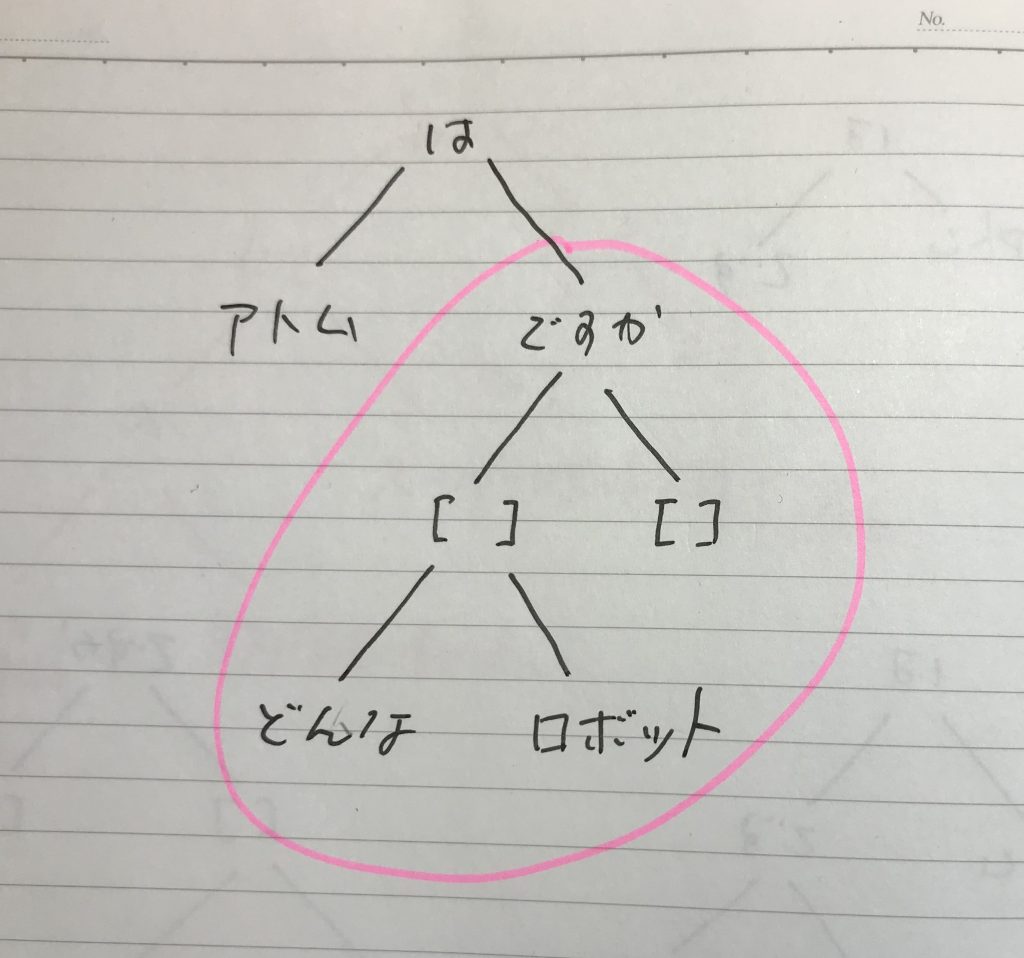
基本これらの違いは、「部分知識を取り出す上でどちらが望ましいか」だが、こちらは、赤い枠の中に、アトムが入っていないのが気になる。しかし、まあ、prolog二分木としてはどちらも有効である。
どちらを生成するかという問題になるが、疑問文の生成は、部分知識の取得とは無関係なので、作りやすい方がよく、その点では後者の「どんな」疑問文をつくようにした方がいい。
この場合、生成ロジックは、「です」を「ですか」に変更し、「ロボット」を値にもつ左の葉を一つのnodeとして「どんな」を左のは「ロボット」を右のは、ノード値は空リスト [ ] にすればよい。
プログラムは、先ほどの「なんですか」疑問文を少し変えた次のようなものになる。
%% ----- どんな 疑問文 -----
donna(T,Out) :- not(functor(T,node,3)),Out=T.
donna(node(N,L,R),Out) :-
(
'です'=N,
not(functor(L,node,3))
-> N1='ですか',
L1=node([],'どんな',L), %% ← 変更点
R1=R
; (
'は'=N
-> N1='とは'
; N1=N,
true
),
donna(L,L1),
donna(R,R1),
true
),
Out = node(N1,L1,R1).
変更点は、一行だけである。 「ですか」の左文字を、部分木に変えたことである。その際、元々の左語をそのノードの右葉にして左は、「どんな」という疑問詞を入れたことである。
まあ、この L1=node([],'どんな',L) 書き方は、CとかJavaとかやっているものには、なんとも変な感じである。なぜなら、node([],'どんな',L)というのは、いわゆる関数ではない。functorという複合項目、ある意味、文字のようなものなのであるが、Lというのは、prologにおける正真正銘の変数である。変数が前触れもなく、裸のままで入っている。prologは、これが半角大文字であることの一点で、変数とみなすのである。しかも、L1=node([],'どんな',L)の演算子"="は、Cやjavaでいう代入処理ではない。ユニフィケーション(単一化)という。L1が何も確定していない変数であるので、結果的に、やっていることは代入なのであるが、元々の機能は、とんでもなく違っている。例えばこれが、node(N,L1,R)=node([],'どんな',L)とかなっていたら、Nが未確定変数ならば、Nには、[]が代入される。確定変数ならば、両者の一致性がチェックされ出力される。変数が確定しているか未確定かによって結果は違ってくる。ユニフィケーションの場合、未確定語が左あろうが右にあろうが関係ない。
ユニフィケーションは不思議な操作ではあるが、prologの根幹を成している機能であるから、とても大事なのである。
このプログラムの実行結果は次のようになる。
?- ['quetion.swi']. true. ?- donna(node(は,[アトム, 'S:普/C:自然物/D:科学・技術'],node(です,[ロボット, 'S:普/C:人工物- の /D:科学・技術'],[ ])),Out). Out = node(とは, [アトム, 'S:普/C:自然物/D:科学・技術'], node(ですか, node([], どんな, [ロボット, 'S:普/C:人工物- の\n/D:科学・技術']), [])).
相変わらず形態素情報は維持されて複雑に見えるが、結果は、先の図のようなものである。