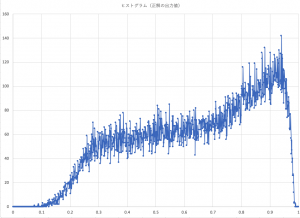
先に助詞の使い方を学ばせたAI(ディープラーニングさせたニューラルネットワークというのが長いので、単にこう言うことにする)に与えられたフレーズの中の一つの助詞を選択させた。その一部を下に示している。助詞そのものは、160フレーズくらい取り上げているが、実際には、データの少ない、稀にしか使われない助詞は、AIはほとんど選択しない。
4語のフレーズである。[ ]で表しているのが、実際に使われていた助詞。その次の ( )の中に、AIが推定した助詞と、そのスコアが示している。上位3位までが記載している。結構外しているが、言葉として悪いとまでは言えない。
外国人が日本語を話すとき、違和感のある助詞を使うことが結構あり、それが外国人らしいわけだが、そう言う違和感が少ない方がいい。
まあ、このシステムも使えるのではないかと思っている。100万フレーズで学習させたが、データは、1000万以上あるので、それを使えば、もう少し改善するかもしれないが、何しろ学習時間がかかる。
No.10 ソ連 [ の ] (は:0.3630, が:0.1074, と:0.0657)イスラエル の No.11 部門 [ は ] (は:0.4477, も:0.0971, が:0.0948)これ に No.12 伊能 [ の ] (の:0.9223, が:0.0109, と:0.0103)収益 は No.13 旭天鵬 [ において ] (の:0.5412, が:0.1425, は:0.1016)断髪式 で No.14 配置 [ は ] (は:0.2043, の:0.1557, が:0.0794)M16 と No.15 全国野球振興会 [ を ] (を:0.7053, で:0.0437, が:0.0365)務め て No.16 系統 [ が ] (の:0.5002, は:0.1054, と:0.0645)ナビ の No.17 上 [ で ] (の:0.2693, で:0.1684, や:0.0647)電波 の No.18 1954年 [ に ] (に:0.3260, は:0.1242, の:0.0659)パリ国立高等音楽院 に No.19 右派 [ の ] (の:0.8765, や:0.1142, による:0.0180)政治家 など No.20 冬期 [ と ] (と:0.4136, は:0.1240, に:0.0923)なる が No.21 これら [ の ] (の:0.9499, は:0.0109, という:0.0054)培養皮膚 は No.22 標準 [ の ] (の:0.7044, は:0.0623, で:0.0341)圧縮比 が No.23 仁王 [ は ] (の:0.2422, は:0.2047, が:0.0913)運慶 の No.24 愛知県がんセンター [ の ] (の:0.7821, を:0.1101, が:0.0507)研究所 に No.25 ジェーン [ は ] (の:0.5065, と:0.1337, は:0.1181)アルティメッツ の No.26 偽名 [ として ] (を:0.8573, で:0.0346, も:0.0249)使っ て No.27 旅客 [ は ] (の:0.2721, は:0.2641, が:0.0778)大都市近郊区間 を No.28 幕府 [ は ] (の:0.1775, は:0.1584, が:0.1229)金 の No.29 恩師 [ の ] (の:0.8917, を:0.0346, が:0.0148)薦め で No.30 男女共同参画社会基本法 [ の ] (の:0.9504, は:0.0108, による:0.0105)規定 による データスキップ = 信用格付業者::は::証券取引等監視委員会::が No.31 139 [ の ] (は:0.3732, の:0.1103, で:0.0970)アメリカ人 の No.32 段ボール箱 [ の ] (の:0.8884, や:0.0135, を:0.0119)応用 で No.33 高 [ で ] (の:0.8250, で:0.0346, は:0.0272)火入れ が No.34 山下敬吾 [ に ] (の:0.5780, と:0.0956, は:0.0678)1敗 の No.35 大半 [ は ] (の:0.5944, は:0.1356, に:0.0576)ミヤコーバス が No.36 アリーナ [ は ] (の:0.3456, は:0.1212, と:0.0864)パフォーミング・アーツ・センター が No.37 料金 [ は ] (は:0.3200, が:0.1131, の:0.1130)30万円 と No.38 龍造寺隆信 [ の ] (の:0.9836, による:0.0049, も:0.0040)死後 は No.39 違法 [ の ] (の:0.6740, を:0.0612, が:0.0483)経営 に No.40 観光道路 [ の ] (の:0.8684, という:0.0395, や:0.0193)性格 も No.41 ala [ が ] (は:0.2413, の:0.1734, が:0.1581)最大 の No.42 ストレイト [ を ] (は:0.6187, の:0.0653, を:0.0452)標的艦 と No.43 夫 [ の ] (は:0.4473, が:0.1373, と:0.0572)ロバート・ロペス と共に No.44 恩師 [ の ] (の:0.8946, を:0.0244, という:0.0132)薦め も No.45 反射 [ の ] (の:0.2507, は:0.2121, を:0.1552)前部 に No.46 肉 [ と ] (が:0.3772, を:0.1449, は:0.1141)驚く ほど No.47 1985年 [ の ] (に:0.3914, は:0.1182, の:0.0777)ベストセラー と No.48 持つ [ を ] (を:0.6830, の:0.2856, が:0.0529)筆頭 として